시계열 데이터
파이썬은 날짜가 어렵다. 나중에 시계열 분석할 때 파이썬으로 핸들링 하게 될 때 어려움을 겪을 수 있으니 잘 이해해두면 좋겠다.
아래의 모듈을 로드한다.

from datetime import datetime
import time
1. 오늘 날짜

오늘 날짜는 datetime.now() 로 리턴하며, 연, 월, 일, 시, 분, 초, 나노세컨드 까지 출력된다.

datetime.today()로도 똑같은 결과를 리턴할 수 있다.

d1의 type를 확인해보면 datetime이라는 타입이 출력된다.
2. 날짜 파싱
1) strptime
- 벡터 연산 불가
in R) as.Date(), strptime
예) 문자열(scalar)의 날짜 파싱
'2024/01/30' + 1 이 방법은 연산이 불가하다 → 날짜 파싱이 필요함.
d2 = datetime.strptime('2024/01/30', '%Y/%m/%d')
d2 + 1 이 방법도 불가하다. 날짜타입과 숫자타입의 연산이 불가하기 때문이다.
+1 의미도, 1일을 더하는지, 한 달을 더하는지, 1년을 더하는지 알 수가 없다.
또한 날짜 파싱은 벡터 연산도 불가하다.
예) Series의 날짜 파싱

시리즈의 형태로는 날짜 파싱이 불가하다.

이 방법으로도 날짜 파싱을 할 수 없다. str은 string 타입만 접근 가능하기 때문이다.

map 과 lambda의 결합으로 해결이 가능하다.
2) pd.to_datetime ★

pd.to_datetime으로 날짜 파싱이 가능하다.
3) 날짜 포맷 변경
- 날짜.strftime(변경하고자 하는 포맷)
- 벡터 연산 불가
예) Scalar 날짜 포맷 방식

예) Series 날짜 포맷 변경
strftime도 벡터 연산이 불가하며, str로도 할 수 없다.
따라서 map + lambda로 리턴하여야 한다.

4. 날짜 추출

위처럼도 가능하지만
dir(d1) 을 하면, 즉 datetime 객체가 호출 가능한 메서드 목록을 확인하면 날짜 추출에 사용할 수 있는 메서드가 있다.

year, month, day 메서드를 사용하면 숫자 타입으로 된 날짜를 리턴할 수 있다.
연습문제
emp.csv 파일을 읽고 입사일 기준 입사일의 요일 별 급여의 평균을 구하여라.



5. 날짜 연산
1) 날짜와 날짜 연산
time delta : 타임 갭
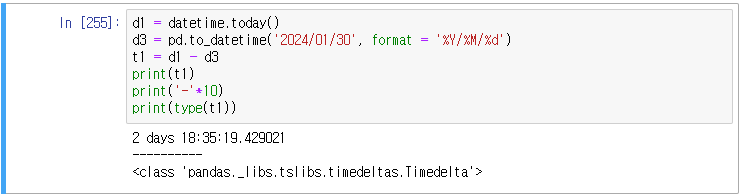
type 결과가 time delta가 출력된다(날짜의 gap을 표현).
위의 t1은 2 days 18:35:19.429021 로 출력이 되는데, 여기서 일만 추출하기 위해서는,

이렇게 출력이 가능하다.
2) 날짜와 숫자의 연산
- 일반적으로 날짜와 숫자의 연산은 불가하다.
d1 + 100 하면 에러가 떨어진다.
2-1) timedelta
예) 100일 뒤

from datetime import timedelta 를 로드 한 뒤 timedelta 옵션에 days를 넣으면 된다.
그러나 개월 수에 대한 연산은 불가하다. months가 없기 때문이다.
2-2) pd.DateOffset
모든 날짜의 timedelta를 다 가지고 있다.

위와 같이 연산 가능하다.
'배우기 > 복습노트[Python과 분석]' 카테고리의 다른 글
| [복습] Python 시계열 데이터(2) (0) | 2024.02.04 |
|---|---|
| [복습] Python | 분석 | 랜덤포레스트(Random Forest, RF)(2) 마무리 (0) | 2024.02.01 |
| [복습] Python multi-index(2) (0) | 2024.02.01 |
| [복습] Python 또 다른 형태의 교차표 생성(pd.crosstab, pivot, pivot_table) (0) | 2024.02.01 |
| [복습] Python long data ↔ wide data 변환(stack, unstack) (0) | 2024.02.01 |



