in R) stack / unstack, reshape2::melt(long data로 만들기), dcast(wide data로 만들기)
** long data / wide data 차이
1. long data
- join 연산 가능
- group 연산 용이
- DBMS에 저장되는 형식
2. wide data
- 교차표
- 요약정보(가독성이 좋음)
- 행별, 열별 연산이 용이
- join 불가 ★
- 시각화, 범주형 분석 시 필요
1. unstack: long data → wide data
df1.unstack(level = -1, # unstack 처리할 level (-1이 디폴트, 맨 마지막 레벨)
fill_value)
예) 일반적인 unstack 처리

위 데이터를 unstack 처리를 하여보자.
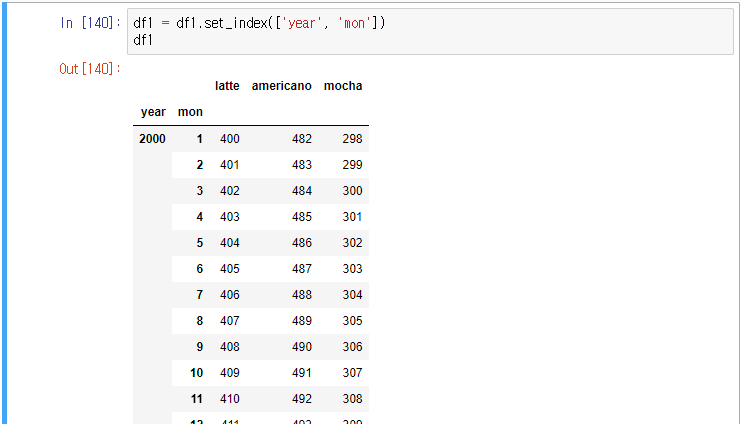
파이썬은 멀티컬럼을 지원하므로 wide 결과도 멀티 컬럼으로 도출된다.

mon 이 컬럼 방향으로 펼쳐진 wide data가 출력되었다.

unstack할 레벨을 level = 'year' 이렇게 작성하면 unstack 처리할 level을 지정할 수 있다.
fill_value 옵션 예제

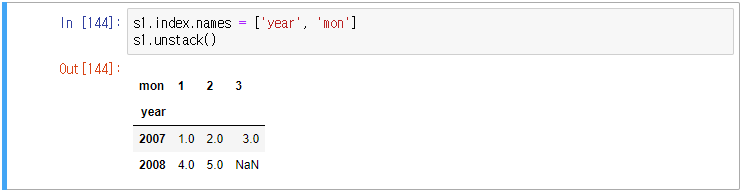
위 s1를 unstack 하면 2008년 3월이 NaN 값이 출력된다. 이 NaN 값을 0으로 출력하고자 한다면 다음과 같이 fill_value 옵션을 사용하면 된다.
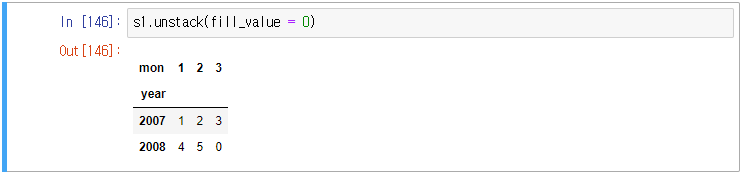
하지만 fill_value 옵션이 아니라 fillna 메서드로도 가능하다.

2. stack: wide data → long data
df1.stack(level = -1, # stack 처리할 level 번호 또는 이름
dropna = True) # NA행 제외
예) 일반적인 stack 처리
unstack 테스트 했을 때 데이터를 다시 불러들어왔다.

stack 메서드를 사용하면 DBMS에 쌓을 때의 데이터 형식으로 변환된다.
예) dropna 예제
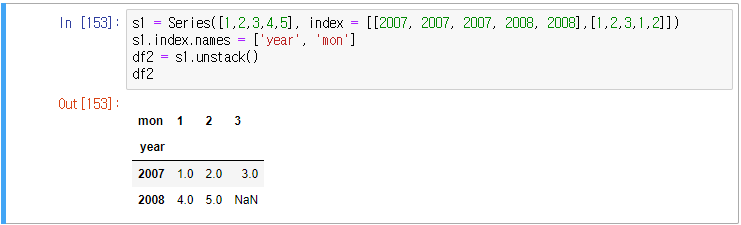
df2와 같은 데이터가 있을 때 stack으로 데이터 형식으로 바꾸어보자.

NA를 가지고 있는 cell은 행으로 만들어지지 않는다(dropna = True 가 default 이기 때문).

이렇게 하면 NA 행이 생략되지 않고 출력이 된다.
연습문제
emp.csv 파일에서 부서별, job별 평균연봉을 교차테이블 형태로 출력하여라.


위처럼 나타내거나 또는,

행과 열을 바꿔 출력이 가능하다. 어떤 레벨을 unstack 할 것인지 명시하면 출력 형태가 바뀐다.
'배우기 > 복습노트[Python과 분석]' 카테고리의 다른 글
| [복습] Python multi-index(2) (0) | 2024.02.01 |
|---|---|
| [복습] Python 또 다른 형태의 교차표 생성(pd.crosstab, pivot, pivot_table) (0) | 2024.02.01 |
| [복습] Python | 분석 | 불순도 + 하루끝(20240129) (0) | 2024.02.01 |
| [복습] Python 파이썬의 정규식 표현식 (0) | 2024.01.31 |
| [실습문제] 2024. 1. 26.(금) (2문제) (0) | 2024.01.30 |



