https://metime.tistory.com/328
[복습] Python 시계열 데이터(datetime, strptime, strftime, pd.to_datetime, timedelta, pd.DateOffset) (1)
시계열 데이터 파이썬은 날짜가 어렵다. 나중에 시계열 분석할 때 파이썬으로 핸들링 하게 될 때 어려움을 겪을 수 있으니 잘 이해해두면 좋겠다. 아래의 모듈을 로드한다. from datetime import datetim
metime.tistory.com
위 게시글에 이어서 시계열 데이터를 확인해보자.
6. 날짜 연속 출력
pd.date_range(start, # 시작 날짜
end, # 끝 날짜
periods, # 끝 날짜가 정해져있지 않은 경우 시작날짜로부터 몇 기간을 지정할 것인지 날짜 추출 개수(기간)
freq=’D’) # by값. 즉 날짜 증가값. D. 1일씩 증가하는 개념
장점: 날짜 파싱을 하지 않고 문자를 입력해도 날짜의 값으로 변환해줌

매일의 데이터를 출력한다(freq = 'D').

freq = '7D' 로 설정해주면 7일씩 증가한다.

freq = 'W' 는 매주 일요일 결과를 출력해준다.
시작 값을 1월 1일이라고 해도 W 자체가 매주 일요일이 default이다.

freq = 'W-MON' 으로 설정하면 월요일이 출력된다.

매 월의 마지말 날이 출력된다.

그 해의 마지막 날이 출력된다.

WOM은 weeks of month의 약자로, 매 월마다 셋 째주 이런 출력을 하고자 할 때 사용되며 위는 매 월 두 번째 목요일을 출력하게 된다.
7. 날짜 색인
- index가 날짜값으로 표현되어 있는 경우 특정 날짜 색인이 가능(날짜의 추출 없이)

index가 날짜로 되어있다.
날짜 색인이라고 하는 것은 아래와 같다.

2월 데이터 전부를 가져오고자 한다면,

특정 월에 접근이 가능하다.
위와 같은 원리로 특정 연도의 접근 또한 가능하다.

슬라이스도 가능하다.

파이썬에서 주가 데이터를 가져오는 방법이 있다.
영업일(주식 개장일) 기준
우선 cmd에서
pip install exchange_calendars
을 실행하여 설치한다.
import exchange_calendars
모듈을 업로드 한 뒤,
exchange_calendars.get_calendar에 한국 주식코드('XKRK') 전달하여 캘린더를 다운받는다.
아래와 같이 is_session 메서드로 날짜를 넣어 True, False 여부를 확인하면 되겠다.

갑자기 생기는 대체 공휴일은 업데이트가 되지 않을 수도 있겠다.
연습문제
부동산_매매지수.csv 파일을 읽고 2008년 4월 7일부터 매주 관찰된 데이터를 가정하여,

여기서, pd.read_csv 의 옵션 중 skiprows = [0, 2] 의미는
첫 번째, 세 번째 행을 생략하라는 의미이다.
또한 위 데이터를 보면 520번 행부터 NaN이 많이 보이는데, 이는 엑셀 자료에서 사용자가 엔터를 쳤거나 공백을 만들어서 나온 NA 값이다. 위 데이터를 NA를 없애면, 다음과 같다.

how = 'all' 옵션을 주면, 특정행 또는 열에서 모든 값이 NA(결측치)일 때 해당 행 또는 열을 삭제하는 옵션이다.
all 대신 any를 주면(default), 하나 이상의 NA인 행 또는 열을 삭제하므로 주의하여야 한다.
1) 2008년 각 지역별 매매지수 평균을 출력하여라

2) 연도별 각 지역별 매매지수 평균 출력

8. 날짜 resample
- 날짜의 빈도를 줄이거나 높이는 방식
- 날짜별 그룹핑 기능 구현 가능
- 날짜가 index 설정 되어있을 경우 가능
예) 연도별 정리된 데이터를 → 월별로 바꾸거나,
월별로 정리된 데이터를 → 연도별로 바꾸거나
이런 걸 resample 이라고 함(frequency를 조절)
연도에서 월이 되면 더 많은 날짜가 되는데 이걸 up-sampling 이라고 한다(더 많은 빈도수, 더 많은 날짜로 분리).
월에서 연도로 되면 날짜가 줄어드는데 이걸 down-sampling 이라고 한다(날짜의 결합).
위 연습문제에서 풀었던 부동산 매매지수 파일로 테스트 해보자.


df1.resample('Y').mean()을 하게 되면 연도별로 그룹핑이 된다.
groupby를 쓰지 않아도 되고 year를 따로 추출하여 계산하지 않아도 된다.
예) down-sampling
- df1은 7D로 구성된 frequency → year frequency로 바뀜
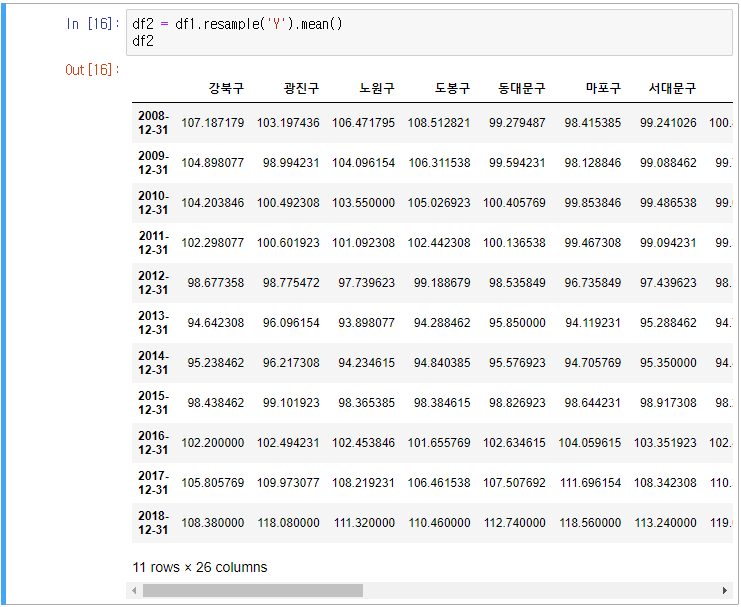
예) up-sampling
- df2를 월 별로 쪼개고자 한다.

df2.resample('M').asfreq() 를 하면, 중간에 나열되는 데이터는 원래는 없는 데이터이므로 갭만 만들어져서 NaN으로 채워진다.
이러한 경우,
df2.resample('M').asfreq().fillna(0) 하여 0으로 NA를 채우거나,
df2.resample('M').asfreq().ffill() 하여 앞 숫자로 채우거나 할 수 있다.
'배우기 > 복습노트[Python과 분석]' 카테고리의 다른 글
| [복습] Python 시각화(2) 선그래프 (0) | 2024.02.07 |
|---|---|
| [복습] Python 시각화(1) (0) | 2024.02.07 |
| [복습] Python | 분석 | 랜덤포레스트(Random Forest, RF)(2) 마무리 (0) | 2024.02.01 |
| [복습] Python 시계열 데이터(datetime, strptime, strftime, pd.to_datetime, timedelta, pd.DateOffset) (1) (0) | 2024.02.01 |
| [복습] Python multi-index(2) (0) | 2024.02.01 |



