시계열 분석 중 LSTM은 분석 시 업데이트를 수행함.
이 말의 의미는, 시계열 모형이 가지고 있는 단점부터 파악해보자면 바로 직전 데이터로 다음 관찰 일을 예측하는 것이다.
그 다음 STEP은 예측값을 가지고 예측을 하게 된다. 그 다음 STEP은 또 예측한 가상의 값으로 예측을 수행하게 된다.
따라서 시간이 지날 수록 의미가 감소하는 것이다.
그러므로 업데이트라고 하는 것은, 예측한 값이 예측을 하는 행위를 막는 방법이다.
처음 설정된 train data로 다음 값을 예측하는 것은 의미가 있다. 그러나 predict value가 predict value를 예측 하는 것은 오차가 있으므로, 예측한 predict을 train으로 합쳐서 다시 그 다음을 예측하게 되는 것이다.
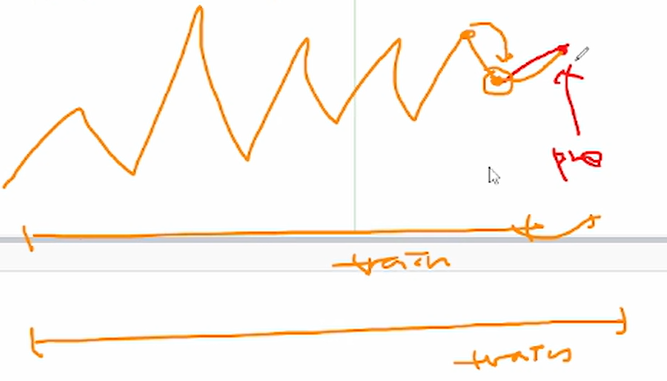
위 그림처럼 예측한 값이 다시 train data로 포함되어 다시 그 다음 예측을 수행하게 된다.
그러나 이런 업데이트를 하는 것 조차도 가상 데이터로 train 시키는 것인데, 이 점이 ARIMA 모형의 한계이다.
위 같은 과정도 직접 코드를 짜서 수행하여햐 한다.
ARIMA같은 경우 짧은 기간 예측은 맞출 확률이 높으나 기간이 길면 예측 성능이 떨어진다.
위에서 설명했듯 언젠가는 예측한 데이터로 예측할 수밖에 없기 때문이다.
그래서 업데이트를 반영하더라도 특정 기간 이상의 예측 결과를 얻기 힘들다. 따라서 ARIMA는 이론적인 측면으로 봐두도록 한다.
업데이트는 시계열 모형에 대한 딥러닝으로 구현하면 좋아질 것이다. 그래서 실제 ARIMA는 쓸 일이 거의 없다.
전 시간의 분석을 계속 이어가보도록 하겠다.
7. 평가
1) train/test 분리

2) 모델링

똑같이 1, 1, 1 이 도출된다.
3) 예측
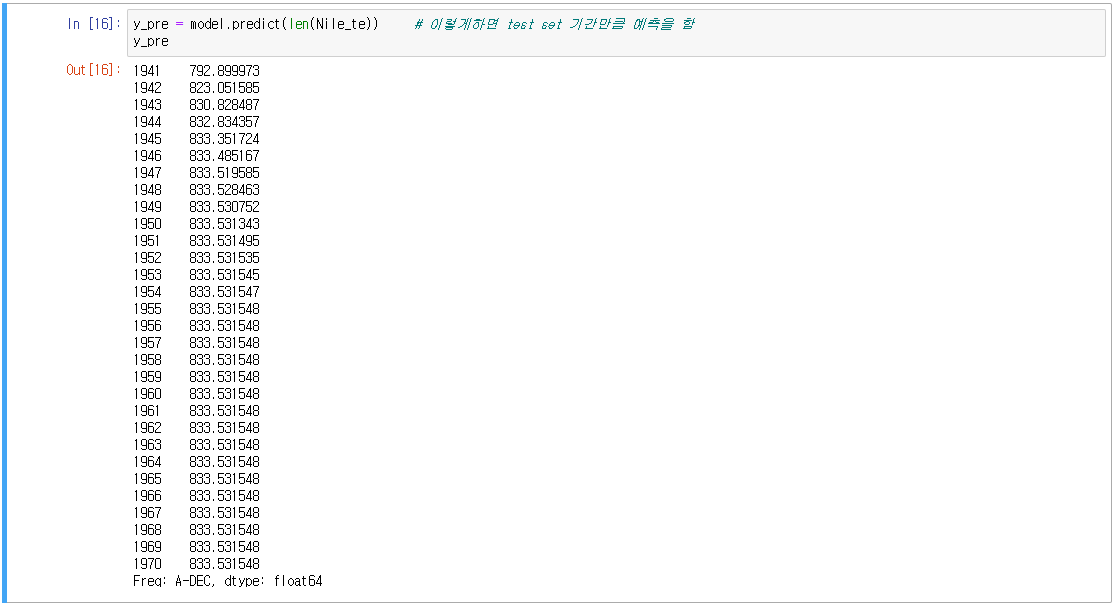
뒤로갈수록 값이 일정하다. 처음에 설명했듯 업데이트를 하지 않으면 뒤로 갈수록 값이 같은 엉터리 모델이 구현되기 때문이다.
4) MSE

MSE = Σ(Y_TRUE - Y_PRE)² / (n-1)
8. 예측 결과 확인(시각화)

한계: 미래 예측을 위해서는 데이터가 계속 업데이트 되어야 한다.
(바로 직전 데이터로 다음 기간의 값을 예측하는 모형은 결국 예측값으로 그 다음 기간을 예측하게 되는 현상 발생)
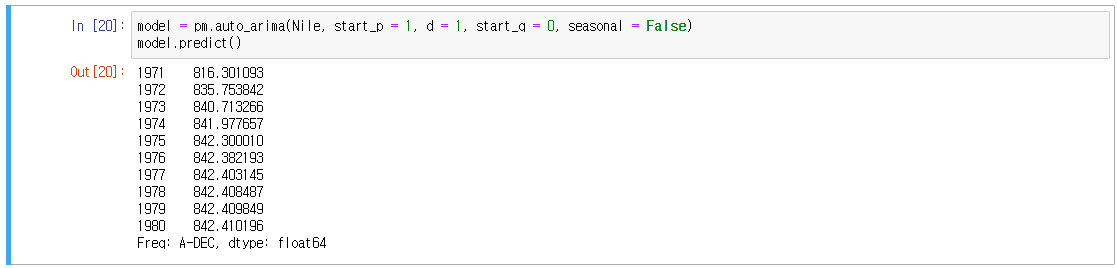
9. 실제 예측
'배우기 > 복습노트[Python과 분석]' 카테고리의 다른 글
| [복습] Python | 분석 | 딥러닝(ANN) - stopping rule 적용 (0) | 2024.04.01 |
|---|---|
| [복습] Python | 분석 | 딥러닝(ANN) (0) | 2024.04.01 |
| [복습] Python | 분석 | 군집분석(5) (0) | 2024.03.06 |
| [복습] Python | 분석 | 군집분석(2) (0) | 2024.03.05 |
| [복습] Python | 분석 | 회귀분석(2) - (전통)회귀분석 총정리 + 하루끝(20240215) (0) | 2024.03.04 |



