1. unique
- 중복 제거값(distinct value 확인)
- 정렬 동반

2. duplicated
- 중복 여부를 리턴(boolean)
- 중복 여부를 확인하는 용도
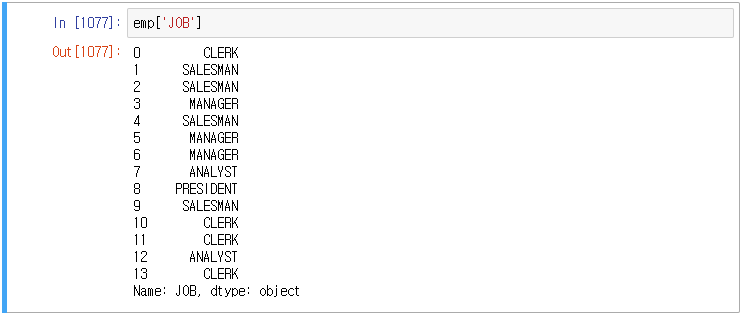
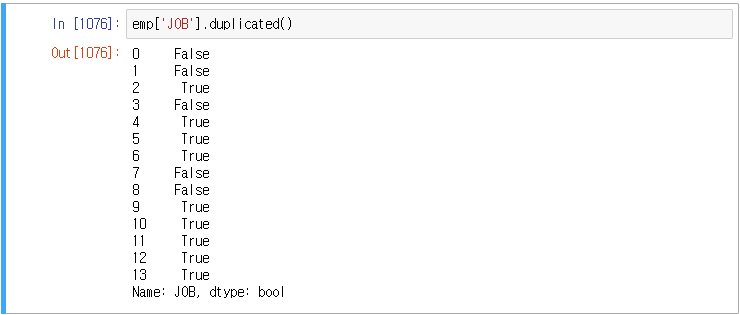
처음 값은 맨 처음에 나온 값이므로 중복이 되지 않아 False로 리턴된다. 두 번째 값도 첫 번째와 다른 값이므로 False가 나온다. 그런데 세 번째는 SALESMAN은 두 번째와 값이 같으므로 True로 리턴된다.
위 메서드를 이용하여 unique value를 추출하기 위해서는 다음과 같이 코드를 짜면 된다.

unique 메서드가 존재하므로 잘 사용하지는 않을 것이다.
3. drop_duplicates
- 중복값 제거 ★
emp.drop_duplicates(subset, # 대상(중복 체크 할 대상). 여러 개 나열 가능(리스트화)
keep = 'first', # first(중복값 중 첫 번째 중복값 남기기), last(마지막 중복값 남기기), False(중복 전부 제거)
ignore_index = False)
1차원에서 데이터 중복을 제거하는 것과 2차원에서 데이터 중복을 제거하는 것은 다르다.
먼저 1차원을 살펴보자.

1차원 객체의 unique value 를 확인하는 방법이다. 그러나 unique 메서드가 있으므로 잘 안쓰게 될 것 같다.
2차원 예시를 살펴보자.

위처럼 두 데이터프레임을 생성 후 병합하면 위와 같은 데이터프레임이 만들어진다.
10번 부서 데이터 컬럼이 중복될 것이다.
이때 drop_duplicates()를 사용하면 어떻게 되는지 확인하여보자.

전체 컬럼과 관련해서 중복을 체크하게 된다.

특정 컬럼을 지정하게 되면 명시된 컬럼만 중복된 경우 삭제를 한다.
'배우기 > 복습노트[Python과 분석]' 카테고리의 다른 글
| [복습] Python 자료구조(4) (array) (0) | 2024.01.26 |
|---|---|
| [복습] Python 집합연산자(union, intersection, difference, np.union1d, np.intersect1d, np.setdiff1d, pd.merge) (0) | 2024.01.25 |
| [복습] Python 데이터 병합(pd.concat) (0) | 2024.01.25 |
| [복습] Python Series와 DataFrame의 특성(reindex, add, sub, mul, div) (0) | 2024.01.25 |
| [복습] Python 정렬(sort_index, sort_values) (0) | 2024.01.25 |



