728x90
반응형
1. 같은 key끼리 연산
아래와 같은 series를 정의하였다.

두 시리즈의 합 연산)

서로 같은 index(key)를 갖는 값끼리 연산
서로 다른 key를 갖는 경우 key의 합집합의 결과를 리턴하기 위해 아래와 같이 각 객체의 모든 key에 대해 reindex 처리 후 연산 → NA 리턴

아래와 같이 처리하면 연산이 가능하다.

reindex를 넣고 fillna를 처리 후 연산하는 것이 복잡하면 다음의 메서드를 사용할 수 있다.

위 결과는 s1 + s2와 같다.
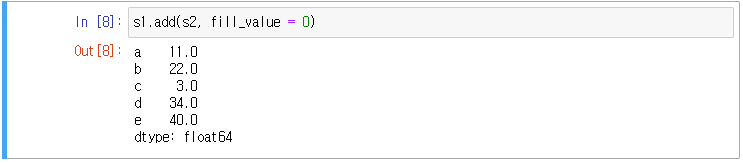
s1 + s2의 연산 결과에 NA리턴을 방지한다(원래 값 유지)
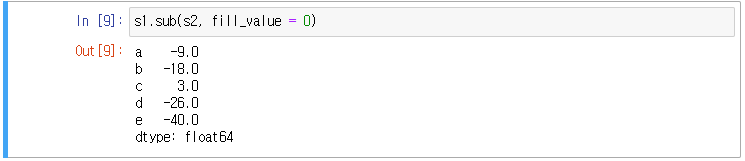
두 시리즈의 빼기 연산)
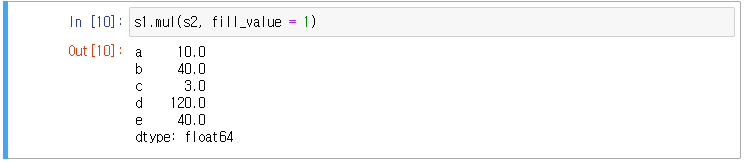
두 시리즈의 곱 연산)
두 시리즈의 나누기 연산

add, sub, mul, div 메서드는 사칙연산만 제공하므로
s1.reindex(list('abcde')).fillna(1) * s2.reindex(list('abcde')).fillna(1)
이렇게 reindex + fillna 방법도 기억하고 있는 것이 좋겠다.
2. index 재배치 가능

reindex로 index를 재배치 할 수 있다.

없는 키 만들기도 가능하며 없는 키를 만들면 NaN이 리턴된다.
예) 두 데이터프레임 연산

위와 같은 데이터프레임을 정의하였다.
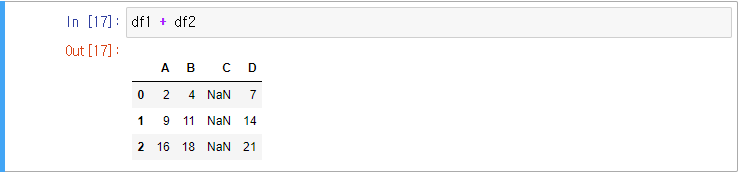
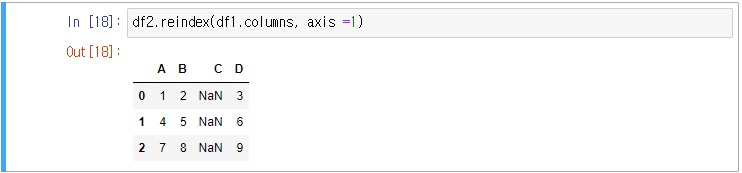
위는 df2의 key 구조를 df1과 동일하게 설정하는 방법이다(컬럼 재배치)
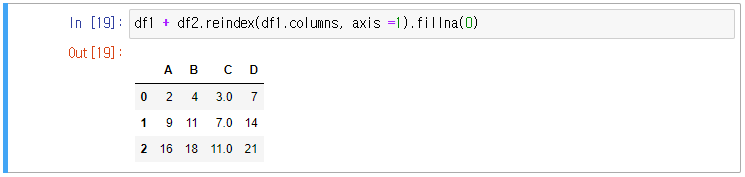
NA가 리턴되는 쪽의 NA를 수정 후 연산하면 NA 없이 연산할 수 있다.

데이터프레임에서도 add 메서드로 연산이 가능하다.
728x90
반응형
'배우기 > 복습노트[Python과 분석]' 카테고리의 다른 글
| [복습] Python 중복값 처리(unique, duplicated, drop_duplicates) (0) | 2024.01.25 |
|---|---|
| [복습] Python 데이터 병합(pd.concat) (0) | 2024.01.25 |
| [복습] Python 정렬(sort_index, sort_values) (0) | 2024.01.25 |
| [복습] Python 데이터의 이동(shift) (0) | 2024.01.25 |
| [복습] Python 파이썬에서의 SQL문법(pandasql 패키지 sqldf 함수) (0) | 2024.01.24 |



