그룹연산이 필요한 경우에 대하여 파악하여보자.
예) emp.csv 파일을 읽고 부서별 최대 급여자 이름을 출력해보자.


이런식으로 매 행 돌아가는 과정이 transform 과정이다.
SQL로 따지면 상호연관 서브쿼리이기도 하다.

여기까지가 transform의 원리이다.
각 행마다의 그룹 연산 결과를 보장해준다. 즉 각 행마다 그룹연산 결과를 붙여주는 것이다.
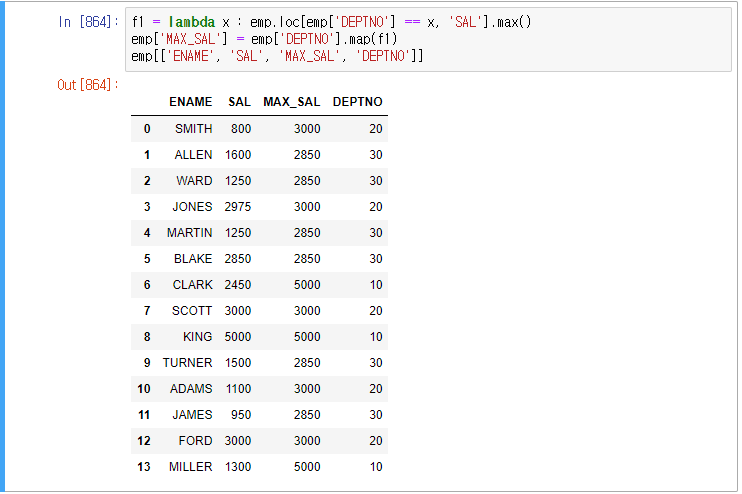
여기서 SAL이랑 MAX_SAL이랑 같냐 라는 것을 R에서는 ddply의 subset이 계산을 했다.

이렇게 최종적으로 부서별 최대 급여자를 호출하게 된다.
in sql) 상호연관 서브쿼리
SELECT *
FROM EMP E1
WHERE SAL = (SELECT MAX(SAL)
FROM EMP E2
WHERE E2.DEPTNO = D1.DEPTNO)
위와 같은 계산 과정을 python에서는 groupby 메서드를 사용하여 간단히 나타낼 수 있다.
문법을 먼저 살펴보자.
- 대상.groupby(그룹핑컬럼).연산함수(연산대상)
- 대상.groupby(그룹핑컬럼)[연산대상].연산함수()
emp.groupby(by, # 그룹핑 컬럼
axis = 0, # 연산방향(0: 세로 방향, 1: 가로 방향)
level, # 그룹핑할 레벨 이름, 번호 전달
as_index = True # 그룹핑 컬럼의 인덱스화 여부
sort = True, # key 정렬 여부
group_keys = True, # (본문과의 중복 출력을 방지하기 위해) index에 그룹핑컬럼 출력 여부
dropna = True) # groupby에 na가 있으면 자동 drop 시켜라는 의미
** groupby 객체가 호출할 수 있는 메서드(메뉴얼에는 안나옴)
1) apply : 사용자 정의 함수에 groupby로 fetch된 결과를 전달 시 사용
df1.apply와는 다른 메서드이다.
사용자 정의 함수를 그룹바이에 적용할 용도이다.

예를 들자면, 위 과정은 불가하다.
AttributeError: 'DataFrameGroupBy' object has no attribute 'sort_values' 라는 에러 메시지가 뜨는데, groupby 객체가 sort_values 정렬 메서드를 직접 호출이 불가하기 때문이다.
따라서 apply 를 사용하면 아래와 같이 출력이 가능하다.

위 코드의 의미는 부서번호(DEPTNO) 내에서 SAL 끼리 정렬하라는 의미이다.
즉, apply에 의해 groupby 객체 일부(데이터프레임 형태)가 함수 내부로 들어가 sort_values를 호출하는 형식이 가능하다는 의미이다.

group_keys 옵션을 False로 끄면 본문 정보와 중복되는 앞에 있는 DEPTNO 를 출력하지 않는다(위 캡쳐와 비교).
부서별 SAL 정렬을 다른 방법을 통해 하여보자. 위 방법은 강제로 하는 방법이라 좋은 방법은 아니다.

사실 sort_values는 위와 같이 사용함으로써 그룹바이 연산처럼 사용할 수 있도록 sort 해주는 메서드이다.
나중에 sort_values 배울 때 다시 공부할 예정이다.
2) agg : 동시에 여러 연산 함수를 전달할 때 사용하는 메서드

3) transform

우선 위 방법은 R에서 ddply의 summarise 처럼 각 그룹별 데이터를 요약해서 출력해주는 방식처럼 화면에 출력하는 방법이다.

이렇게 하면 모든 행에 대하여 전부 출력된다. R에서 ddply의 transform 처럼 전체 데이터 길이에 맞게 매 행마다 각 그룹별 연산 데이터 출력한다.
그러면 emp['MAX_SAL'] = emp.groupby('DEPTNO')['SAL'].transform('max') 를 넣으면 되겠다.
groupby 예제이다.
예) 부서별 평균 급여를 출력하시오.

또는

이렇게 출력할 수 있는데 , 선생님은 첫 번째 방법을 권하셨다.

as_index 옵션을 False로 끄면 그룹핑 컬럼을 index가 아닌 본문에 배치를 할 수 있다(데이터 프레임 리턴)
as_index = False 로 사용하지 않더라도 데이터 프레임으로 리턴할 수 있는 방법이 있다.

index를 본문에 배치하면서 데이터프레임으로 리턴이 가능하다.

이런 방식으로도 데이터 프레임 리턴이 가능하다.
예) 부서별 평균 급여와 평균 COMM을 출력하시오.

예) 부서별, JOB 별 평균 급여를 출력하시오.

파이썬 groupby 결과는 index로 groupby를 표현하는 것이 기본이다보니 여러 개 값을 가지고 동시에 그룹핑 하다보면 멀티인덱스로 표현이 될 수밖에 없다.
그래서 파이썬에서 멀티 인덱스를 많이 표현하므로 멀티인덱스를 잘 이해하여야 한다.
출력 결과는 SERIES로 리턴된다.
예) 외부 객체와 axis를 사용한 컬럼 그룹핑

다음과 같은 데이터프레임이 있다.

위와 같이 g1 변수에 리스트를 설정하고 groupby에 외부 객체를 넣어 연산도 가능하다.
예) 멀티 인덱스를 갖는 데이터 프레임에서의 레벨별 그룹핑

위와 같이 멀티 인덱스를 갖는 데이터 프레임을 설정하였다.
연도별로 합을 출력하여보자.

다음은 상하반기로 합을 출력하여보자.


위와 같이 출력이 되도록 데이터를 만들어보자

연습문제를 풀어보자
student.csv 파일을 읽고

1) 학년별 키 평균

2) 성별 키, 몸무게 평균

먼저 g1에 성별을 저장하였다.

그리고 외부 객체 g1를 groupby에 넣음으로써 성별 키와 몸무게의 평균을 산출하였다.
처음에 내가 풀이할 때에는 성별 컬럼을 만들어서 넣고 내부 객체를 이용하여 groupby를 했는데 그러면 데이터가 지저분해지는 걸 느꼈다. 앞으로는 외부객체를 이용하는 방법도 고려해보아야 겠다.
연습문제
병원현황.csv 파일을 읽고

잘린 코드는
df2 = pd.read_csv('C:/Users/*****/Documents/병원현황.csv', encoding = 'cp949', skiprows = 1)
이다.
1) 시군구명칭, 표시과목 index 설정

2) 항목, 단위 컬럼 제거

3) 각 행마다 같은 연도끼리의 총 합

4) 연도별 병원수가 가장 많은 구 확인

먼저 이렇게 하면 연도별로 각 구의 병원 수의 합이 출력된다(계 행 포함하여 sum 하긴 했음).
그 다음에 연도별로 병원 수가 가장 많은 구를 추출하려면 다음과 같이 출력하면 된다.

5) 계 행 제거

6) 구별, 연도별 병원수가 가장 많은 표시과목 확인

'배우기 > 복습노트[Python과 분석]' 카테고리의 다른 글
| [복습] Python 파이썬에서의 join(pd.merge) (1) (0) | 2024.01.22 |
|---|---|
| [복습] Python DBMS 연동 (1) | 2024.01.22 |
| [복습] Python wide data에서의 최대/최소 index값 추출(idxmax(), idxmin()) (0) | 2024.01.18 |
| [실습문제] 2024. 1. 17.(수) (2문제) (0) | 2024.01.18 |
| [복습] Python multi-index(1) (0) | 2024.01.17 |



