파이썬은 여러 레벨의 index, column 설정이 가능
가장 상위 레벨부터 0, 1, 2, ... 레벨 숫자 부여하여 지정
레벨 별로 정렬하며 그룹핑이 가능하고 삭제 또한 가능
1. 생성
멀티 인덱스는 아래와 같은 형식의 index 이다.

멀티 컬럼은 아래처럼 설정된 컬럼이다.
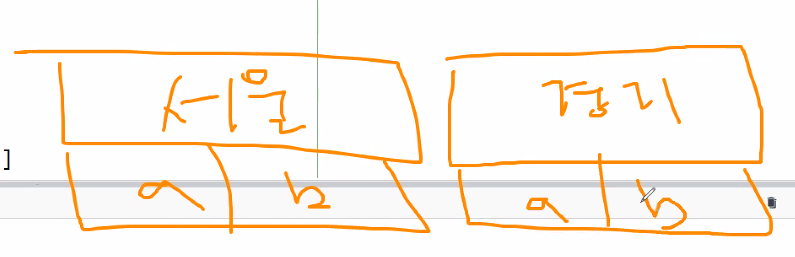
설정은 아래와 같이 할 수 있다.
df1.index =[[상위레벨], [하위레벨]]
df1.set_index = ([상위레벨], [하위레벨])
df1.columns = [[상위레벨], [하위레벨]]
예) index 직접 전달

위와 같은 데이터 프레임을 생성했다면 다음과 같이 멀티레벨 index를 직접 전달할 수 있다.

예) '병원현황.csv' 의 데이터 멀티 레벨 index 설정
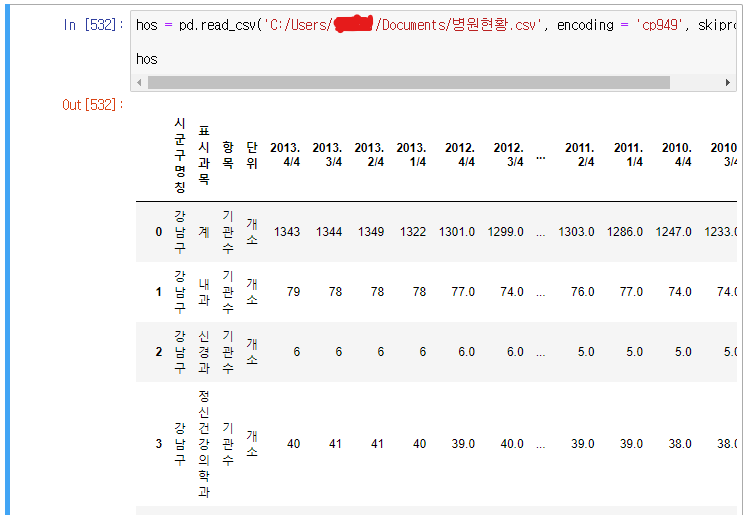
잘려서 보이지 않는 부분은
hos = pd.read_csv('C:/Users/*****/Documents/병원현황.csv', encoding = 'cp949', skiprows = 1) 이다.
위의 시군구명칭과 표시과목을 멀티 레벨 index로 정의해보자.
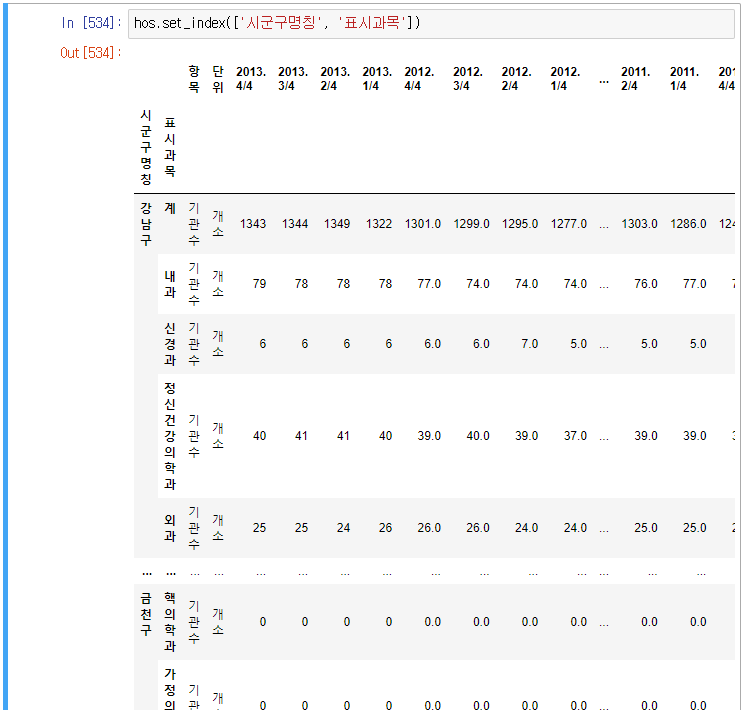
이렇게 바뀐 것을 확인할 수 있다.
index에 이름을 부여해보자.
위에 만들어둔 데이터 프레임(df1)을 활용해보겠다.
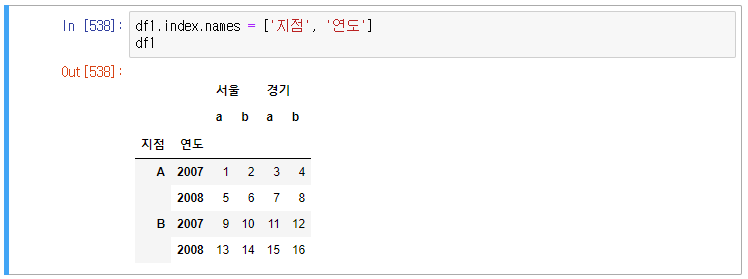
멀티레벨에 이름을 각각 부여하려면 index.names 라고 하여야 한다. index.name 하면 오류가 난다.
컬럼에도 이름을 부여하여보자.

index 이름 삭제

완전히 덮어 쓰는 방식으로 한 쪽만 남겨두고 싶다면 None 대신 한 쪽은 작성한 채로 덮어씌우면 된다.
연습문제를 풀어보겠다.
부동산_매매지수현황.csv 파일을 읽고 컬럼을 멀티레벨로 설정하여라.

df1 = pd.read_csv('C:/Users/*****/Documents/부동산_매매지수현황.csv', skiprows=1, encoding = 'cp949')
참고로 파이썬은 컬럼 이름이 들어가지 않으면 안되기 때문에 빈 란은 Unnamed로 들어가게 된다.
STEP 1) index 설정


STEP 2) 컬럼명에서 Unnamed를 포함하고 있는 영역을 NA로 치환

STEP 3) 컬럼명의 NA를 이전값으로 치환
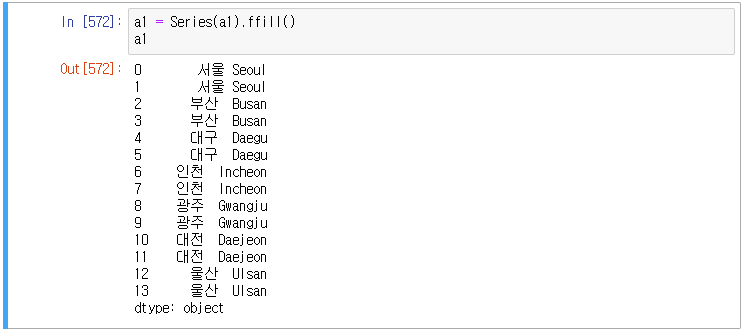
STEP 4) 멀티컬럼 설정
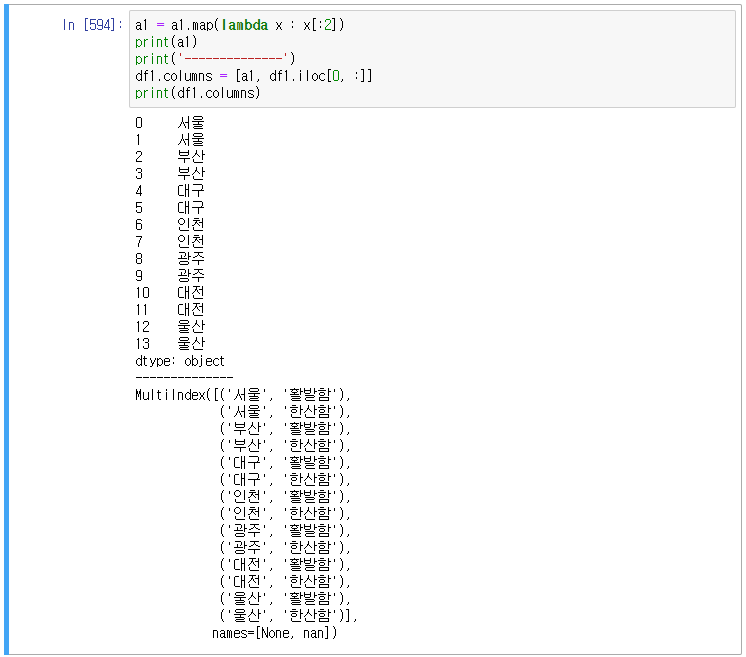
여기까지 하면 다음과 같은 데이터프레임이 만들어진다.

이제 불필요한 행을 제거해겠다.
STEP 5) 불필요한 행 제거

위처럼 위치 기반으로 앞의 두 행을 제거함으로써 세 번째 행부터 끝까지 추출하는 방법이 있다.
다른 방법으로는 drop을 사용하여 NA인 행을 제거하여보자.

drop 메서드에 NA index를 전달 할 수 있다.
마지막으로 표를 깔끔하게 정리해보겠다.
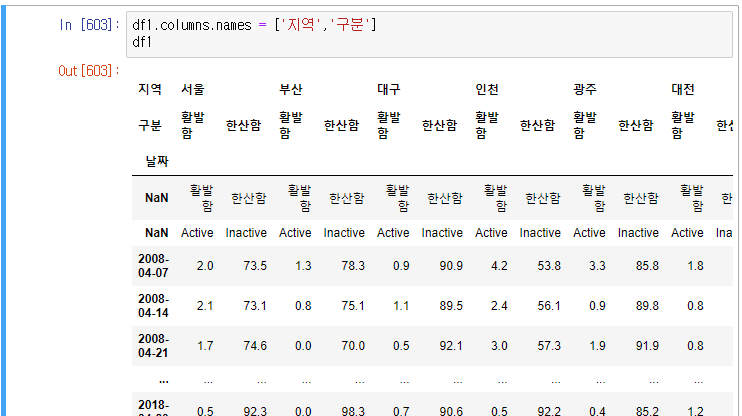
2. 색인
위에서 테스트했던 데이터프레임이다.

상위레벨 컬럼 선택이 가능하다.

상위레벨 index 접근이 가능하다.
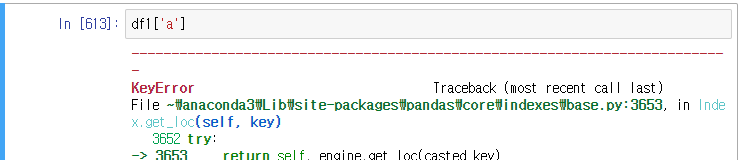
그러나 이와같은 방법으로 하위 레벨의 접근은 불가능하다.

이렇게 하위 레벨의 위치를 이용한 행/컬럼은 선택이 가능하다.
하지만 위와 같은 방법이 아닌 이름을 이용하여 색인을 도와주는 메서드가 있다.
멀티 인덱스의 하위 레벨의 접근
df1.xs(key, # 선택할 행/컬럼 이름
axis = 0, # 방향(행:0, 컬럼: 1)
level = 0, # 레벨 이름 또는 레벨 번호. 상위 레벨이 0, 하위 레벨로 갈 수록 1씩 증가
drop_level) # 레벨 축소 할 건지의 여부. True가 default.
만일 멀티레벨에 이름이 설정되어있다면 level 옵션에서 이름을 직접 불러올 수도 있다.

이렇게 추출이 가능하며, 하위 레벨 이름을 다음과 같이 살릴 수도 있다.
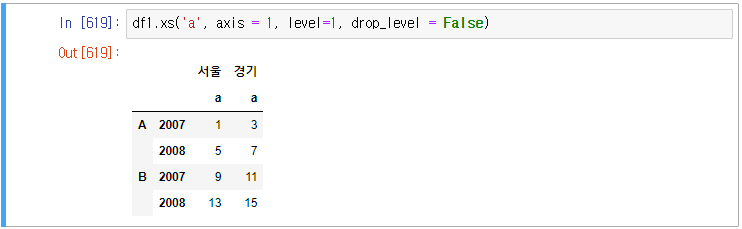
멀티 레벨의 순차적 접근
df1 데이터 프레임에서 서울의 b만 추출을 하고 싶다면 ?
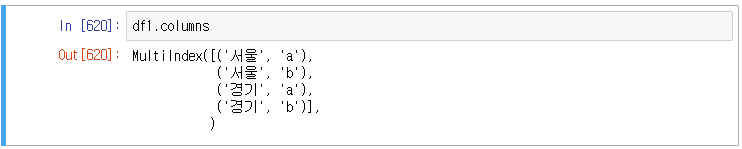
먼저 멀티레벨 컬럼의 형태를 살펴보면, 멀티레벨의 저장은 각 레벨의 값을 묶어서 튜플의 형태로 저장하고 있다.
그렇다면 다음과 같이 추출하여 서울의 b를 추출할 수 있다.

튜플로 순차적 레벨값 전달이 가능하다.

위와 같이 여러 튜플 전달 또한 가능하다.
연습문제
위에서 가공한 부동산_매매지수현황 df2 데이터 프레임을 이용할 것이다.

df2에서 날짜를 년, 월, 일 구분하여 3레벨 인덱스 설정 후

먼저 연/월/일 을 각각 c1, c2, c3에 저장 후
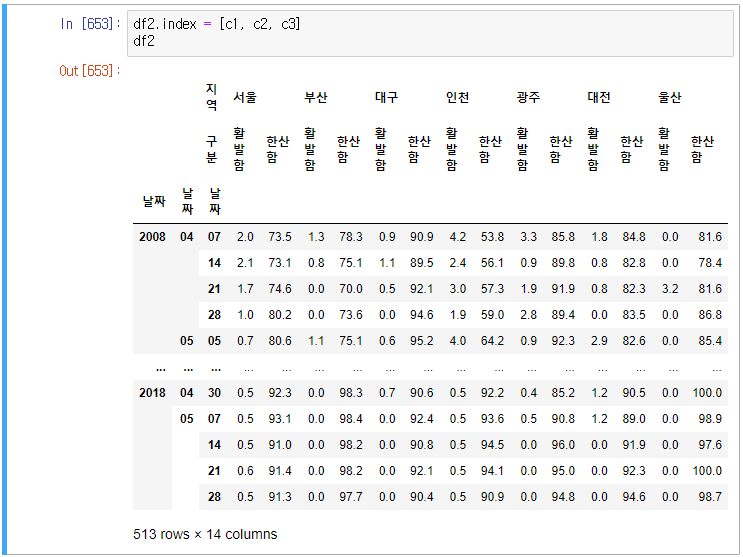
멀티레벨 인덱스로 저장하였다.
1) 2008년 선택

위 방법은 레벨 축소가 발생한다.
레벨 축소를 방지하기 위하여 xs메서드를 사용하고 drop_level 을 False로 지정하면 다음과 같이 출력된다.
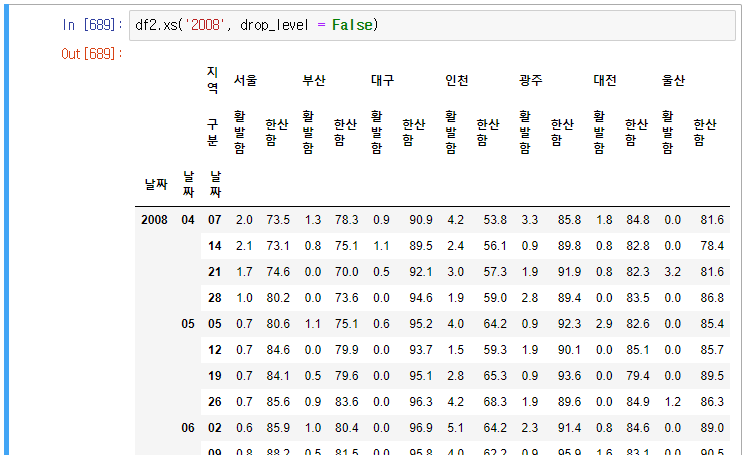

문자의 슬라이스 색인으로도 레벨 축소 방지를 할 수 있다(문자의 슬라이스 색인 시 마지막 범위는 포함된다)
문자 슬라이스는 loc가 제공해준다.
2) 05 월 선택

3) 인천 선택
인천을 선택하는 방식에도 여러 가지 방법이 있다.

직접 추출하는 방법이 있고,

색인을 사용하는 방법이 있고,
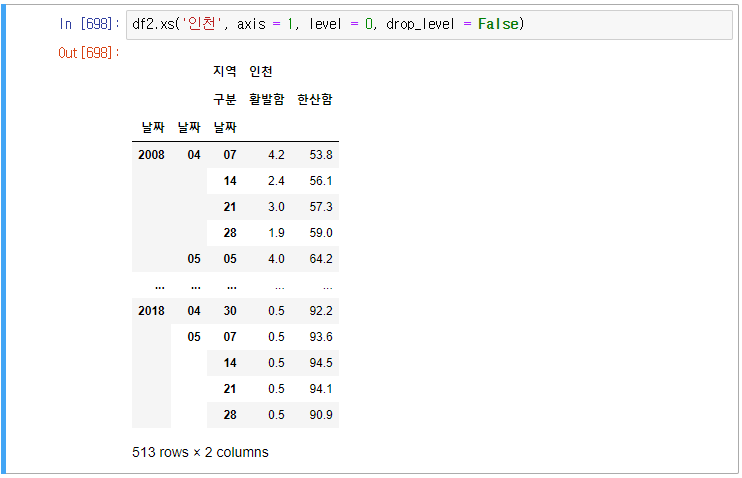
xs 메서드를 사용하는 방법도 있다.
4) 모든 지역의 활발함 컬럼 선택
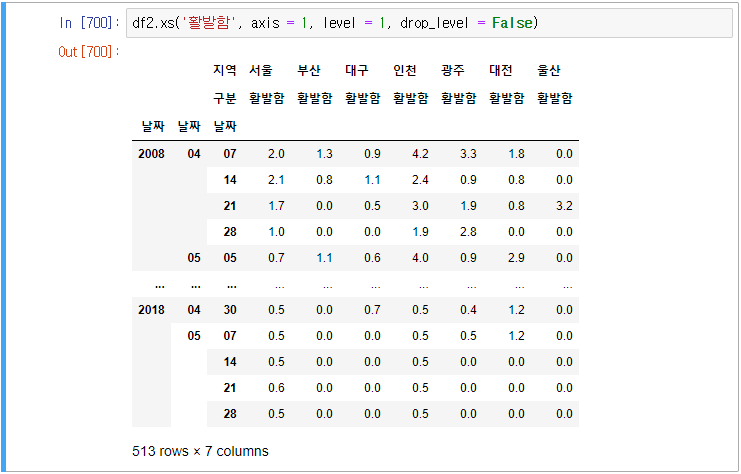
이렇게 추출할 수도 있으며
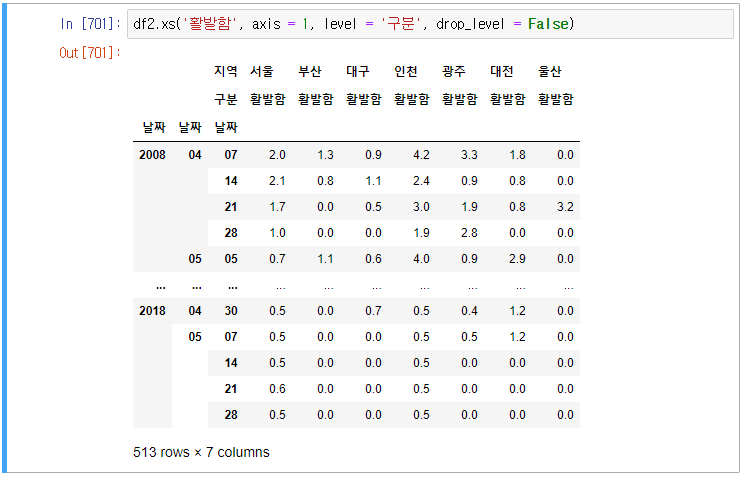
레벨에 index 이름을 넣어서도 추출할 수 있다.
5) 서울의 활발함과 인천의 활발함 선택

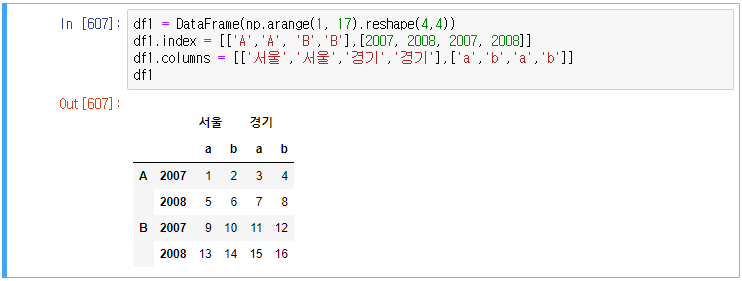
3. 산술연산(멀티레벨을 가질 때의)
위의 df1 프레임으로 테스트 해보자
서울, 경기로 mean 하고자 할 때, 아니면 a 끼리 mean 하고자 할 때 사용하는 방법이다.
예) 컬럼의 상위레벨이 같은 값끼리 합
이 말은 지역이 같은 값끼리 합을 구하게 되면 a, b는 사라지게 된다.
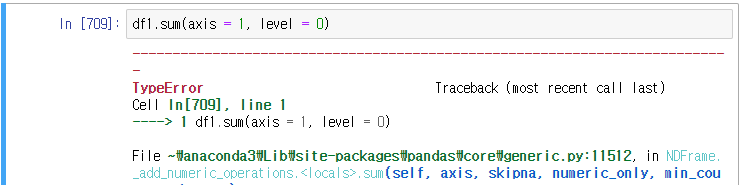
이런 식의 수학통계 메서드는 전달이 불가하다(버전 차이. 전 버전에서는 됐었음.)
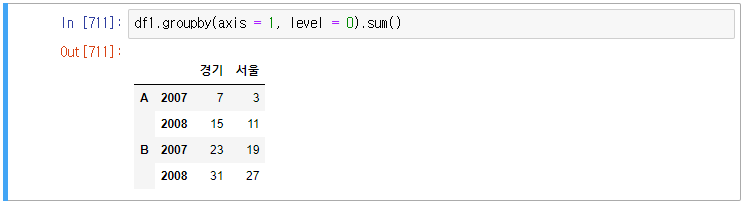
groupby는 정렬을 동반하여 가나다 순으로 컬럼을 정리한다.
예) 컬럼의 하위 레벨이 같은 값끼리의 합
a끼리 합하고자 하는 것은 다음과 같이 나타낼 수 있다.

4. 기타 기능(멀티레벨을 가질 때)
1) drop을 사용한 하위 레벨 값의 삭제 가능
drop으로 df2 프레임(부동산_매매지수현황 가공 데이터 프레임)의 5월을 제거해보겠다.
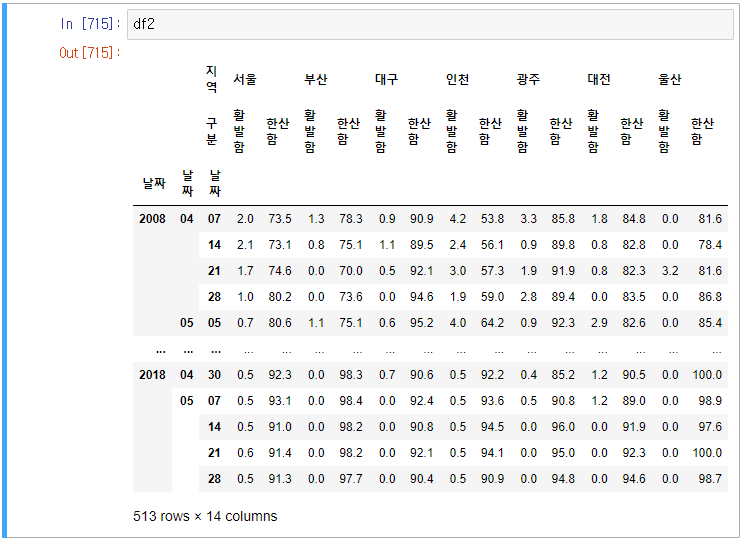
우선 df2 프레임이다.
여기서 5월을 제거해보자.
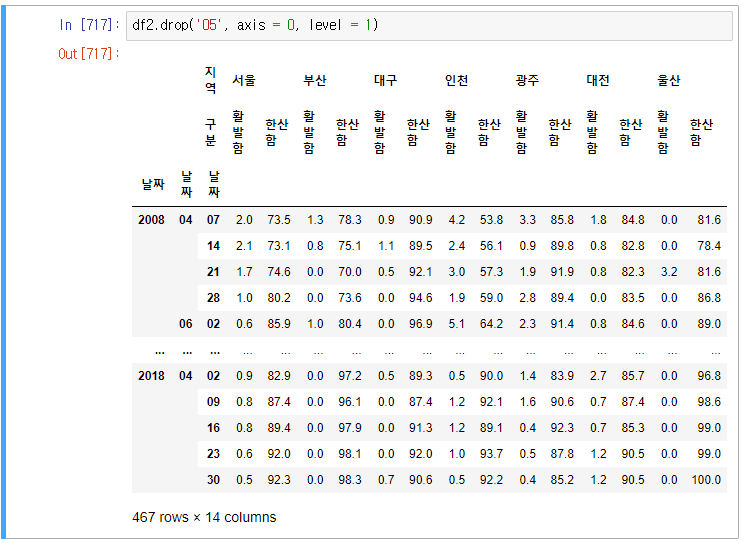
drop으로 df2의 활발함을 제거하여보자.

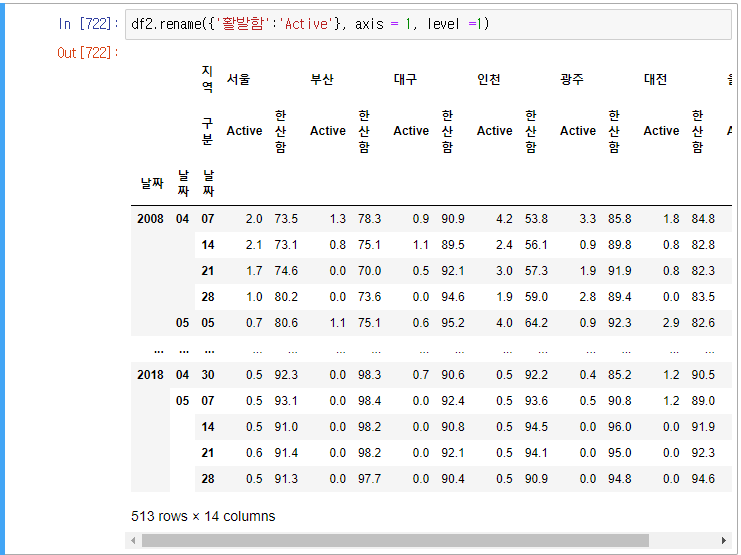
2) rename
활발함을 active로 바꿔보자.
'배우기 > 복습노트[Python과 분석]' 카테고리의 다른 글
| [복습] Python wide data에서의 최대/최소 index값 추출(idxmax(), idxmin()) (0) | 2024.01.18 |
|---|---|
| [실습문제] 2024. 1. 17.(수) (2문제) (0) | 2024.01.18 |
| [실습문제] 2024. 1. 16.(화) (3문제) (0) | 2024.01.17 |
| [복습] Python fillna (NA치환) (0) | 2024.01.16 |
| [복습] Python dropna 메서드(NA를 포함한 행/컬럼 제거) (0) | 2024.01.16 |



