1. apply_test2.csv 파일을 읽고 각 지점(a~d)별 평균을 구하되, 각 결측치 값은 해당 기간의 최소값으로 대치 후 처리하여라

해당 파일을 처리하기 위하여 name을 index로 처리하고 index를 지우겠다.
(본 문제에서 name은 상관 없는 컬럼이므로)

이런 상태로 만들었다.
STEP 1) 천 단위 구분기호 삭제

STEP 2) 숫자 변환 시도(astype) → 결측치 처리 대상 확인
sol1) 결측치 처리할 값을 모를 때 → 하나씩 치환

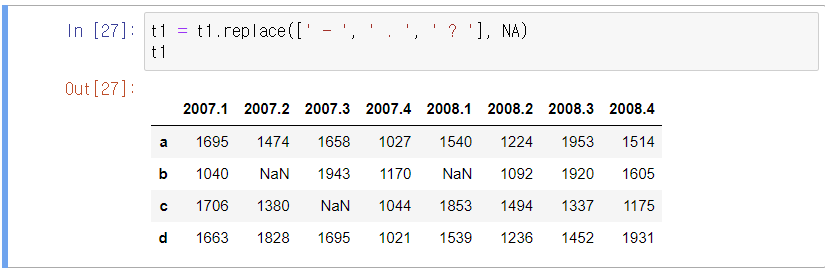
Value Error : invaild literal for int() with base 10 : ' - '
라는 에러가 뜬다. - 라는 문자가 삽입되어 있다는 의미이다.
문제에서 결측치는 해당 기간의 최소값으로 지정하라고 했으나 일단 NA로 치환해두겠다.

다시 int로 변환했을 때 나오는 에러를 살펴보자.

이 때에는 오류메시지가 약간 다르다.
ValueError : cannot convert float NaN to integer
NA값이 있는 경우에는 int로 변환이 불가하다.
파이썬에서는 NA는 float형이므로 astype을 float으로 시도해보겠다.

이 때 에러 메시지는 아래와 같다.
ValueError : could not convert string to float : ' . '
.이 데이터프레임 값에 들어있기 때문이다.
이 값도 NA로 처리하자.

다시 한번 astype으로 float형으로 변환 시도해보자.

다음 에러메시지가 뜬다.
ValueError : could not convert string to float : ' ? '
데이터프레임 값에 ? 를 NA로 대치하겠다.

sol 2) 결측치 처리할 값을 알 때 → 동시에 치환
어떤 데이터 결측치 문자가 들어있는지 알 경우에는 다음과 같이 처리할 수 있다.
mapping rule을 통한 치환도 가능하다.
이제 전체 데이터 타입을 float으로 변경이 가능하다.

STEP 4) 결측치 대치
먼저 각 컬럼별 결측치 수 확인 방법이다.

2007.2 , 2007.3, 2008.1 컬럼에 결측치가 하나씩 존재하는 것을 확인하였다.

위와 같이 컬럼별로 최소값을 결측치 대치 할 수 있으며, 모든 컬럼에 대해 결측치 대치를 한 번에 처리할 수 있는 방법도 있다.

STEP 5) 지점별 연산
마지막으로 지점별 평균값 계산이다.

2. 병원현황.csv 파일을 읽고

1) 항목, 단위 컬럼 삭제

2) 계 행 삭제
자료를 보면 계 행은 drop으로 삭제할 수 있는 행이 아니다. drop은 index로 설정한 것들만 가능하다.

위처럼 처리함으로써 계 제거를 확인할 수 있다.
3) 4사분기 컬럼만 선택하여 저장

위 코드를 풀이하면 아래와 같다.
먼저 세 번쩌 컬럼부터 분기수를 추출하여 4인지 확인한 논리값을 a1에 저장한다.
그리고 앞의 시군구명칭과 표시과목도 추출하기 위하여 두 True 값을 앞에 붙인다.
마지막으로 완성된 논리값 리스트를 이용하여 컬럼을 추출한다.
4) 컬럼이름으로 연도만으로 표현

3번과 같은 풀이방법이다.
연도별 컬럼만 추출하여 연도만 읽어낸다.
연도별 컬럼만 추출하여 hos.columns[2:] = s1 할 수 있을 것 같으나 이런 방법은 불가하다. column 명의 일부만 바꿀 수 없고 전체로 덮어쓰기하여 변경할 수 있기 때문이다.
그래서 앞의 두 컬럼 이름도 불러와서 전체를 덮어쓰기하였다.
3. apply.csv 파일을 읽고

1) date 컬럼을 생성하여라(2019/05/01)

위에 잘린 부분은
df1['year'].astype('str')+'/0'+df1['month'].astype('str')+'/0'+df1['day'].astype('str')
이다.
위 date 형식은 두 자리 월이나 두 자리 일이 아니어서 0을 그냥 붙임으로써 해결하였으나, 만일 두 자리 월이나 두 자리수 일이 있다면 아래와 같이 풀면 되겠다.

zfill을 이용하면 풀이가 가능하다.
date 컬럼을 추가했으므로 date 컬럼이 맨 뒤에 있는 데이터프레임의 형태가 되는데, 만일 이 date 컬럼을 day 컬럼 뒤에 두고 싶다면 아래와 같이 열 순서를 바꿀 수 있다.

사용자 정의 열 순서 재배치로 해결할 수 있다.
2) id, passwd를 분리하고, id/passwd 컬럼은 삭제하여라.
id/passwd 컬럼을 보면 비밀번호가 없는 값이 하나 있다.

10번행 데이터가 ID만 존재한다.
ID를 추출하는 방법은 다음과 같다.

R에서는 가능하지만 파이썬에서 위의 ID 추출방법처럼 passwd 를 추출할 수는 없다.
아래처럼 에러가 발생한다.

IndexError : list index out of range
에러이다. 없는 index를 요구했기 때문이다.
따라서 ID는 위와 같은 방법으로 추출하되 passwd는 다음과 같이 추출하여야 한다.

파이썬은 null이 없다. 그래서 범위에서 벗어난 값을 요구할 경우 파이썬은 스칼라를 null로 리턴할 수가 없어 에러가 발생한다. 이와 같은 경우는 빈 리스트를 출력하도록 하면 된다.
리스트에서 하나의 값을 요구할 때 스칼라로 출력이 되며 이는 차원축소가 발생한 개념과 같다.
그렇다면 차원이 축소되지 않게 리스트로 출력을 하면 에러가 떨어지지 않는다. 다만 추출할 데이터가 없으니 빈 리스트로 리턴이 되는 것이다.
따라서 위 데이터를 빈 리스트로 출력하게 되면 아래처럼 사용하면 된다.

'배우기 > 복습노트[Python과 분석]' 카테고리의 다른 글
| [실습문제] 2024. 1. 17.(수) (2문제) (0) | 2024.01.18 |
|---|---|
| [복습] Python multi-index(1) (0) | 2024.01.17 |
| [복습] Python fillna (NA치환) (0) | 2024.01.16 |
| [복습] Python dropna 메서드(NA를 포함한 행/컬럼 제거) (0) | 2024.01.16 |
| [복습] Python numpy / pandas 수학통계 함수(메서드) 차이 (0) | 2024.01.16 |



