이미지와 영상은 픽셀 사이즈만 맞추면(영상은 프레임 단위로 쪼개는 것이 중요) 된다.
그리고 딥러닝 학습 시 입력값이 수치로 변환되어야 한다(output 또한 수치).
또한 딥러닝, 머신러닝에서 중요한 것은 데이터 품질관리이다.
모델링도 중요하지만 데이터 품질관리가 더 중요하다.
문장의 감성분석의 경우, 긍정/부정을 나누는 것은 분류모델로 모의한다.
인간이 직접 리뷰를 전부 읽고(평점이 있는 경우 긍/부정을 쉽게 구분할 수 있음), 긍정인지 부정인지의 라벨링 작업을 직접 진행하여야 한다. 즉 사람의 눈을 거치는 작업이 필요한 것이다.
평점이 1~5점이 있는 경우, 다섯 개의 라벨링을 거쳐야 한다.
1, 2 점을 부정, 3을 삭제, 4, 5는 긍정 등으로 Y 라벨링의 분석 목적에 맞게 구분할 수도 있다.
모델링을 하는 경우 1, 2, 3, 4, 5 점수 예측 보다는 긍정/부정 예측을 하는 것이 더 모델링 결과가 좋게 나온다. 결과는 확률 모델로 나타나며, 긍정이 몇 %, 부정이 몇 % 판별하는 모델이 나타난다.
이 때 X 데이터들의 전처리가 매우 중요하다.
전처리 과정은 다음과 같다.
1. 형태소 분석(= 말뭉치 분석): 토크나이즈를 통해 단어화 하는 것으로, 구글에서 제공하는 knop(한국어 자연어 처리), 세종사전 등이 있다.
2. 일반화: 조사가 어떻게 붙느냐에 따라 의미가 달라진다.
3. 불용어 제거: 문맥에 필요없다고 생각하는 단어가 불용어이다.
문자 데이터를 수치로 변환하는 작업은 벡터라이저(벡터화)라고 한다. 이 부분을 많이 연구하여야 하는데, 제일 접근하기 쉬운 과정은 count vectorizer이다. 이 과정은 단어의 수를 세는 것으로, 강조하고자 하는 단어가 중복적으로 나타나는 것이 특징이다. 특정 단어가 반복되는 건 분명 그 단어에 의미가 있을 것이라는 전제를 가지고 있다.
자연어 처리 과정
1. 데이터 수집
- 감성 분석, 텍스트 분류: Y의 라벨링 필수
2. 형태소 분석
- 형태소: 일정한 의미를 갖는 가장 작은 단위의 말의 단위(= 단어)
혼자 자립하여 사용할 수 있는 말의 단위(독립적인 의미를 가짐)
예) 책가방 → 책 + 가방
- 형태소 분석: 문장을 쪼개서 여러 단위로 분리하는 과정(토큰화)
- 형태소 분석기: 형태소 분석을 수행하는 모델(토큰화를 진행하지만 때에 따라 일반화를 진행해주는 모델도 있음)
mecap(C/C++), konlp(R), konlpy(python), khaiii(C/C++), khaiii는 리눅스 기반으로 돌아감
3. 불용어 제거
- 불용어 사전(회사의 경우 자사 불용어 사전을 이용함) ** 중요
- 딥러닝 모델 사용
4. 벡터화 **
- 언어 모델에 학습시키기 위해 수치로 변환하는 작업
1) count 기반
- BoW(bag of words): 단어들의 순서를 무시하고 단순히 단어의 포함 횟수를 기반으로 DTM(Document-Term-Matrix) 구성
ex) sklearn의 count Vectorizer
- TF-IDF(Inverse Document Frequency) 변환: 단어 횟수 기반으로 가중치를 부여하나 특정 문장에만 포함되어 있는 단어는 역가중치 부여
count 기반이기는 하나, 많이 반복되는 단어일수록 높은 가중치를 부여하는데, 항상 높은 빈도로 감성 분석에 영향을 주는 것은 아니다.
2) 임베딩(Embedding): 단어를 카운트 기반보다 저차원 공간선상에 매핑하는 과정
예)
문장 1: 옷이 너무 별로네요
문장 2: 배송이 너무 빠르고 옷도 마음에 듭니다.
1) count Vectorizer
너무(0) 든다(1) 마음(2) 별로(3) 빠르다(4)...
문장 1 1 0 0 1 1
문장2 1 1 1 0 1
2) Embedding
1차원 2차원
너무 0.37 0.9 (다른 단어와는 구별되는 공간 부여)
마음 0.8 0.1
장점: 문장 학습할 때 차원이 늘어나지 않음(Count Vectorizer는 새로운 단어가 등장하면 차원이 확장됨)
5. 모델링
1) 나이브 베이즈: 텍스트 마이닝에 특화된 머신러닝 모델
나이브 베이즈만으로도 메일 스팸분류가 잘 되긴 하다. 스팸일 가능성이 많은 단어일수록 거르는 모델이기 때문(문맥 보지 않음)
2) RNN
3) LSTM
4) 기타 파생 모델들
반어법 또는 부정일 때 자주 사용하는 단어들이 긍정이랑 사용되면 해석이 잘못되는 경우가 많다. 그러면 더 많은 데이터를 학습시켜야 한다.
중심 과정은 아래와 같다.
STEP 1) 토큰화 및 일반화
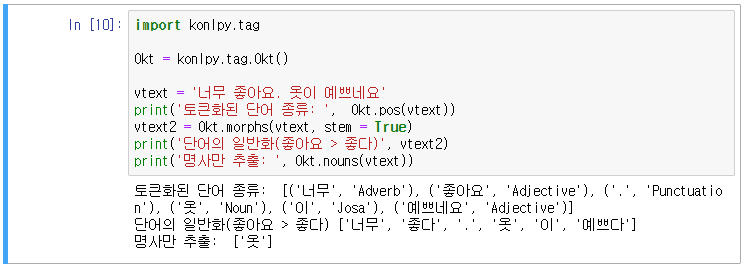
STEP 2) 숫자, 특수기호 제거

STEP 3) 불용어 제거

'배우기 > 복습노트[Python과 분석]' 카테고리의 다른 글
| [복습] Python | 분석 | 감성분석(나이브 베이즈) - 쇼핑몰 후기 감성분석 (0) | 2024.04.14 |
|---|---|
| [복습] Python | 분석 | 감성분석(워드 클라우드) (0) | 2024.04.14 |
| [복습] Python | 분석 | 딥러닝(CNN) 이미지 분석(2) + 하루끝(20240402) (0) | 2024.04.12 |
| [복습] Python | 분석 | 딥러닝(CNN) 이미지 분석 + 하루끝(20240401) (0) | 2024.04.01 |
| [복습] Python | 분석 | 딥러닝(ANN) - stopping rule 적용 (0) | 2024.04.01 |



