- 클래스 불균형: 분류 분석 시 각 클래스의 빈도 차이가 심한 경우
- 클래스 불균형이 심한 경우 다음의 문제 발생
1) 정확한 결정경계 생성이 어려움 → 과적합 발생
2) 예측 점수 신뢰도가 떨어짐
예) 100명 중 97명이 불합격, 3명이 합격인 경우 100명 모두 불합격이라고 해도 accuracy는 97%가 됨(실질적으로는 소수 클래스를 전혀 예측하지 못함 → 소수 클래스 accuracy 0%)
- 다양한 측면에서의 분류 평가 지표를 확인할 필요가 있음.
- 클래스 불균형일 경우 다수, 소수 클래스의 데이터를 조작하는 방식(언더, 오버 샘플링) 고려 가능
- 임계값 이동을 통해 소수 클래스 예측 비율을 조절하는 방식 고려 가능
- 기타 앙상블 기법이나 딥러닝 기법을 통해 클래스 불균형 문제를 해소하는 학습 처리
예) AnoGAN을 사용한 소수 클래스 이미지 생성
데이터 불균형은 탐색하는 타깃 데이터의 수가 매우 극소수인 경우(분류모델일 경우 Y의 각 클래스 빈도 차이가 심할 때) 불균형 데이터 처리를 수행하면 정밀도가 향상됨
** 불균형 처리 방법
언더 샘플링: 클래스의 비율이 높은 쪽을 낮은 쪽 클래스의 빈도에 맞추는 작업. 데이터의 손실이 크고, 중요한 데이터를 잃게 될 수도 있음
오버 샘플링: 소수 클래스 데이터를 복제 또는 생성하여 데이터의 비율을 맞추는 작업. 정보의 손실이 없으나 과대 적합 발생 가능성
임계값 이동: 분류 모델 생성 시 분류 기준을 데이터의 클래스의 비율을 반영하여 임계값을 조절하는 방식(로지스틱 회귀에서 나온 개념, cutoff 이동. 최종 predict value에서 임계값을 이동하는 개념임)
앙상블 기법: 기타 여러 모델들을 혼합하여 사용
** 언더 샘플링: 다수 클래스를 소수 클래스 크기에 맞게 제거
1) 랜덤 언더 샘플링: 랜덤하게 다수 클래스를 선택하여 제거(과적합 심함)
2) ENN(Edited Nearest Neighbors)
- KNN 기법 사용(K >=2)
- 각각의 다수 클래스의 K개 이웃을 확인, 그 중 소수 클래스가 포함되어 있으면 제거
- 결과적으로, 소수 클래스 인근 다수 클래스를 제거 → 결정 경계선을 다수 클래스 쪽으로 이동시키는 효과
3) CNN(Condensed Nearest Neighbors)
- KNN 기법 사용(K = 1)
- 각각의 다수 클래스의 가장 가까운 이웃을 확인(자기 자신 제외), 그 중 다수 클래스가 포함되어 있으면 제거
- 소수 클래스와 먼 데이터 삭제(다수 클래스 집합에서 대표만 남기는 방식) → 결정 경계선 이동하지 않음(decision boundary 변동이 적은 기법)
4) 토멕링크
- tomek link: 소수 클래스와 가까운 다수 클래스 집합
- tomek link 중 다수 클래스 제거
- 소수 클래스 인근 다수 클래스 제거 → 결정 경계선을 다수 클래스 쪽으로 이동시키는 효과
5) OSS
- CNN + 토멕링크
- 다수 클래스를 토멕링크 방식으로 먼저 제거, CNN을 사용하여 대표자만 남기는 방식
예제 - 언더 샘플링 전 후 비교

우선 발생하는 경고들을 다 제거해주었다.
1. 데이터 로딩 및 불균형 정도 확인
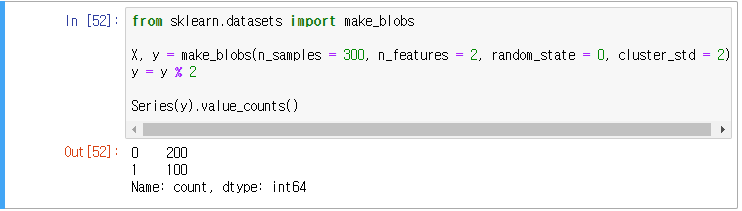
2. 원본 산점도

3. 언더 샘플링 진행
pip install imblearn
imblearn 로딩시 에러: sklearn 버전 호환 문제(아래 링크 확인)
https://metime.tistory.com/356
[Python] imblearn 로딩 에러
sklearn과 imblearn 버전 호환 문제로 imblearn로딩시 에러 발생 1. sklearn 버전만 낮추기 pip uninstall scikit-learn -y pip uninstall scikit-learn -y #위 설치 에러나는 경우 한번 더 pip install scikit-learn==1.2.2 IDE 재시작
metime.tistory.com


4. 시각화 비교

** 오버 샘플링: 소수 클래스 집단을 다수 클래스 크기에 맞게 복제하여 생
1) 랜덤 오버 샘플링
- 소스 클래스 집단을 복원 추출하여 다수 클래스 크기에 맞게 생성
- 소수 클래스와 동일한 데이터가 생기므로 경계선 변화가 적음(무작위로 소수 클래스 복제(복원 추출))
2) SMOTE
- 소수 클래스 기준으로 가장 가까운 K개 이웃을 확인하고, 그 이웃들 사이의 선형 추세를 반영하여 소수 클래스 생성
- 소수 클래스와 다른 데이터가 생기므로 경계선 변화 발생(다수를 향하는 방향으로 임의적으로 생성)
3) Borderline-SMOTE: 경계선에 소수 클래스 생성
- SMOTE와 유사
- 추세 반영 시 소수 클래스 집단과 다수 클래스 집단을 잇는 선형 추세를 반영한 경계 인근에 데이터 생성
- 소수 클래스와 다른 데이터가 생기므로 경계선 변화 발생 → 다수 클래스 쪽으로 이동
4) ADASYN
- SMOTE와 유사
- 데이터 위치에 따라 SMOTE 적용 방식을 다르게 설정
- 인근에 있는 다수 클래스 비율에 따라 생성하는 소수 클래스 수를 달리하는 방식
오버 샘플링 기법들은 경계선 인근에 데이터가 생성되는 기법들이다.
따라서 위의 네 가지 모두 경계선의 이동이 발생할 수밖에 없다.
예제 - 오버 샘플링 전 후 비교
1. 데이터 로딩 및 불균형 정도 확인

2. 원본 산점도

3. 오버 샘플링 진행


4. 시각화 비교

'배우기 > 복습노트[Python과 분석]' 카테고리의 다른 글
| [복습] Python | 분석 | 연관분석(1) + 하루끝(20240214) (0) | 2024.02.14 |
|---|---|
| [복습] Python | 분석 | 상호작용(=교호작용, interaction effect) + 하루끝(20240213) (0) | 2024.02.13 |
| [복습] Python | 분석 | 결측치 처리 (0) | 2024.02.12 |
| [복습] Python | 분석 | 부스팅 이론(2) (0) | 2024.02.12 |
| [복습] Python | 분석 | 부스팅 이론(1) + 하루끝(20240206) (0) | 2024.02.12 |



