백터화 내장된 문자열 메서드
- pandas 제공
- 기본 문자열 메서드가 벡터화가 불가능한 점을 보완
- 시리즈만 호출 가능(DataFrame 호출 불가, 리턴 형태도 Series)
- str.______ 형태로 호출(ex. s1.str.upper())
1. 대소 치환

위와 같은 방법은 에러가 발생한다.
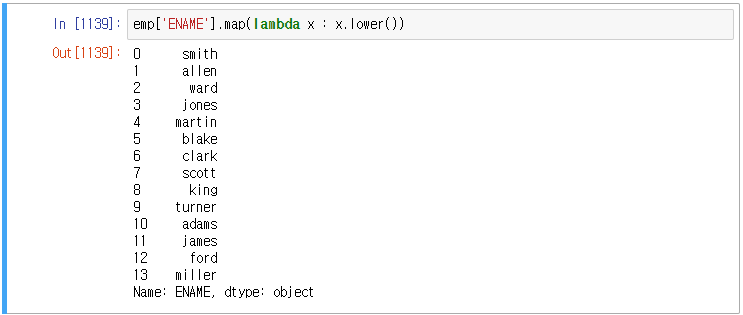
그래서 map과 lambda를 사용하여 각 행마다의 lower 가 적용되도록 했다.
그러나 이제는 str인 벡터화 내장된 문자열 메서드를 사용하면 해결된다.

dir(e1.str) 로 벡터화 내장된 문자열 메서드 목록을 확인할 수 있다.
2. 벡터화 내장된 색인 ★
입사일에서 입사연도만 추출해보겠다.

위처럼 수행하면 Series에서 4개의 원소를 출력한다는 의미이므로 틀린 방법이다.

map을 통해 Series의 원소를 함수에 전달하여 각각 추출이 가능하다.

이제는 벡터화 내장된 색인으로 처리가 가능하다.
3. 문자열 분리

위 방법은 불가하다.

map과 lambda의 결합으로 풀이가 가능하다.
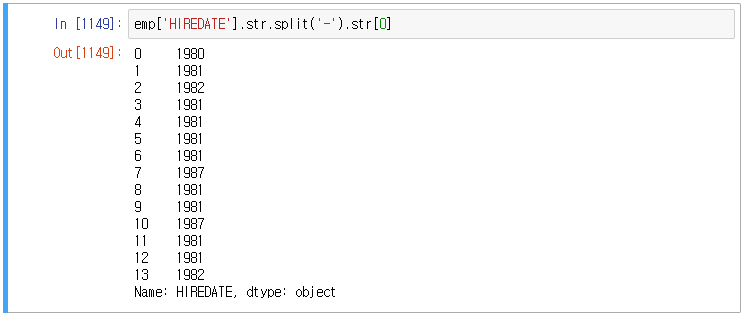
앞으로는 위와 같은 방법으로 처리하겠다.
4. 문자열 치환
- str.replace(old, new) 로 처리
- old, new는 스칼라(문자열)만 가능

str을 사용한 문자열 치환 방식이다.

std['TEL']은 student.csv 파일의 TEL 컬럼인데, 학생들의 전화번호가 담겨있다. 여기서 지역번호를 XXX로 치환하고자 하는데, NaN이 뜬다. 왜냐하면 old value에는 seires가 들어갈 수 없기 때문이다. 그렇게 되면 제대로 된 치환이 불가하여 모두 NA가 출력된 것이다.
예) 데이터 프레임에 문자열 메서드 전달
str.____ 형태로 제공되는 "벡터화 내장된 문자열 메서드"는 시리즈만이 호출 가능하므로 2차원 구조인 데이터프레임에 문자열 메서드 전체 적용시에는 "벡터화 내장된 문자열 메서드"가 아닌 "기본 문자열 메서드"를 사용한다.

card 데이터프레임에서 쉼표(,)를 제거하여보자.

위 방법으로는 해결되지 않는다.
데이터프레임이 호출한 replace는 값치환 메서드이므로 문자열의 일부 치환이 불가하다. 에러는 발생하지 않지만 아무것도 변경되지 않는다.

applymap과 lambda의 결합으로 해결하였다.
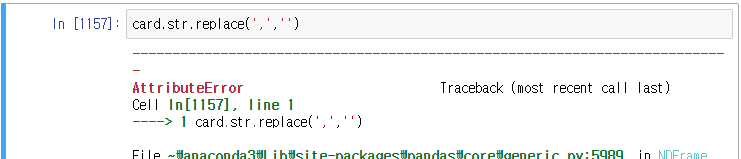
위에서 설명했다시피 card는 데이터프레임이기 때문에 str을 사용할 수 없다.
따라서 기본 문자열 메서드인 replace를 사용하기 위해서는 applymap과 lambda의 결합인 위 방법을 사용하면 되겠고, str.replace를 사용하기 위해서는 series 형태가 input 될 수 있도록 apply와 lambda의 결합을 사용하면 된다.
apply와 lambda의 결합은 아래와 같다.

replace에 대하여 간단히 정리해보자
1) 기본 문자열 형식의 replace
- 스칼라만 가능, 문자열의 일부를 치환할 수 있다.
2) 값치환 메서드
- 데이터프레임 호출 가능
- 완전히 일치하는 값만 치환 가능
3) str.replace
- 1번이 확장된 느낌
- 일부 치환 가능
5. 횟수/길이
1) 문자열 길이

문자열의 길이는 len을 사용한다.

시리즈가 들어가게 되면 시리즈의 원소의 수가 출력된다.
여기서 len 메서드를 사용하면 매 원소마다의 문자열 길이를 추출할 수 있다.

2) 문자열 포함 횟수

count는 해당 문자가 몇 개 포함되는지 출력해주는 메서드이다.

str과 함께 사용하면 series에서도 조건에 맞는 결과 출력이 가능하다.
예제) student.csv 파일을 읽고 전화번호에서 국번을 마스킹 처리하여라.

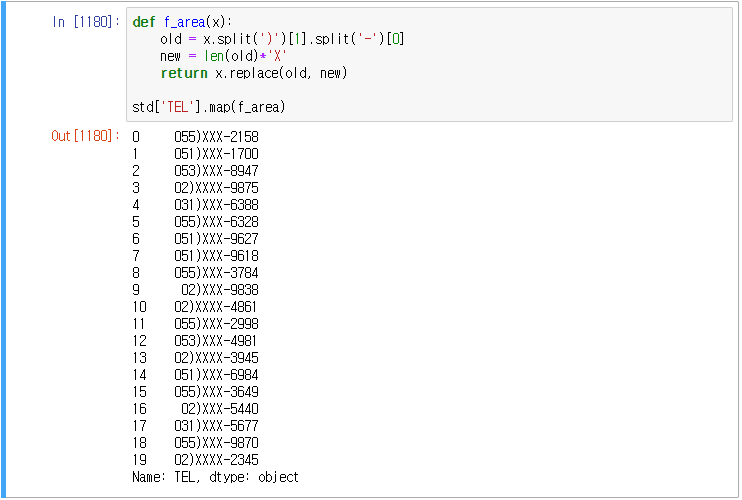
str은 사용하지 않고 풀이하였다.
사실 이 문제는 str을 사용하면 복잡해지기 때문이다.

이러한 방식으로 접근을 하여야 한다.
6. 문자열 포함 ★
- str.contains로 처리(기본 문자열 베서드에서는 제공되지 않음
- 기본 문자열 포함관계는 in 연산자로 가능
예제) emp의 ename에 A를 포함한 직원의 이름, 부서번호를 출력하여라.

이렇게 해결 가능하다.
다른 방법도 많다.
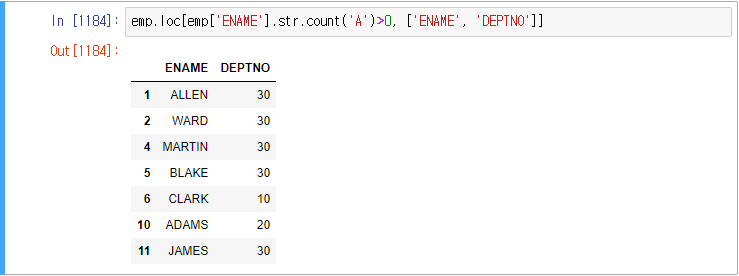
또는,

따라서 정리하면,
'A' in 'ALLEN' 은 문자열(스칼라)의 포함관계
emp['ENAME'].str.contains('A') 은 시리즈의 각 원소의 문자열 포함관계 확인
7. 문자열 결합
- 기본 문자열 메서드는 문자열 결합 메서드가 존재하지 않는다 → 문자열 + 문자열로 전달이 가능
- 기본 문자열 메서드의 join 메서드가 분리구분기호를 반복해서 전달하여 결합해주는 기능을 한다.
- str.cat(기본 문자열 메서드에는 없음), str.join 메서드로 등장
예) 기본 문자열의 결합
'a' + 'b'
예) 시리즈 원소의 결합

매 원소별 결합(분리구분기호로 호출하는 형태)

sep 옵션은 꼭 써주어야 한다. 매 원소별 별합(분리구분기호가 cat 메서드 안에 전달됨)
예) 시리즈 원소 내부 결합

위와 같은 시리즈를 정의하였다.
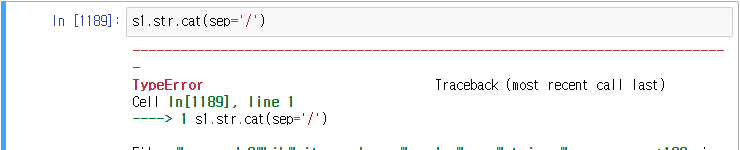
이 경우는 에러가 난다. str.cat 메서드는 문자열 시리즈의 문자열 연결에 사용되는데 여기서는 리스트가 포함된 혼합된 데이터 유형이므로 적용되지 않는다.

join을 사용하면 가로방향 결합이 된다.
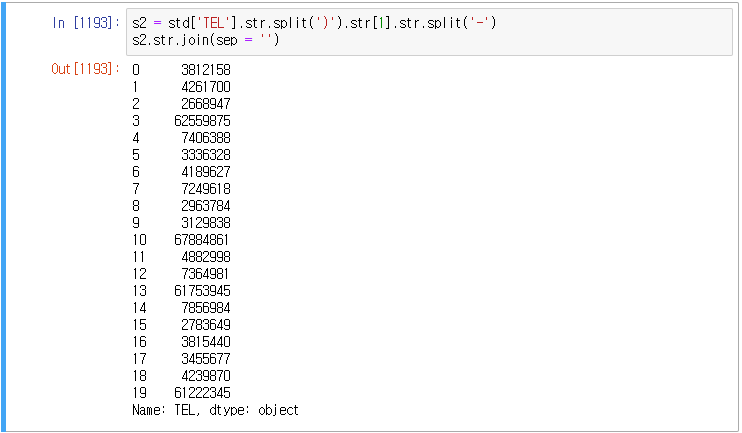
전화번호를 추출하여 지역번호를 제거하고 국번과 전화번호 뒤 네자리를 결합하고자 할 때 사용된다.
8. 문자열 삽입
1) zfill: 왼쪽에 0을 채우는 기능
- 기본 문자열 메서드, 벡터화 내장된 문자열 메서드 모두 제공

2) rjust, ljust: 반대 방향에 문자열을 채우는 기능
- 기본 문자열 메서드, 벡터화 내장된 문자열 메서드 모두 제공

이렇게 테스트가 가능하다.
3) pad: 양방향 문자열 채우는 기능
- 벡터화 내장된 문자열 메서드에만 제공
mon.str.pad(width, # 총길이
side = 'left', # 채울 방향 [left, right, both]
fillchar = ' ') # 채울 문자열

연습문제
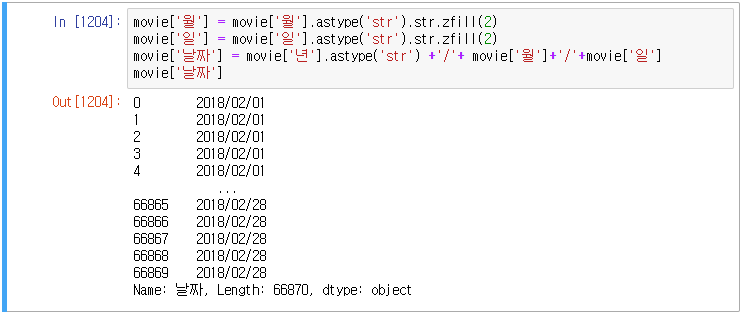
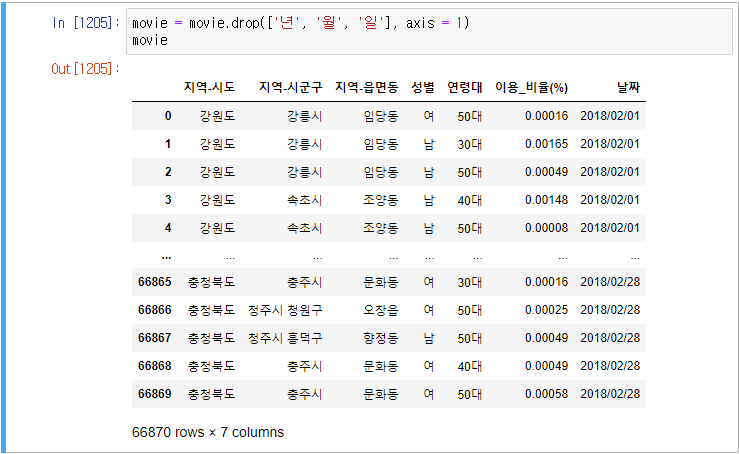
movie_ex1.csv 파일을 읽고 년월일 컬럼을 결합하여 새로운 '날짜' 컬럼을 생성하여라(맨 앞에 배치), 그리고 년, 월, 일 컬럼을 제거하여라(2018/02/01 형태로 생성)
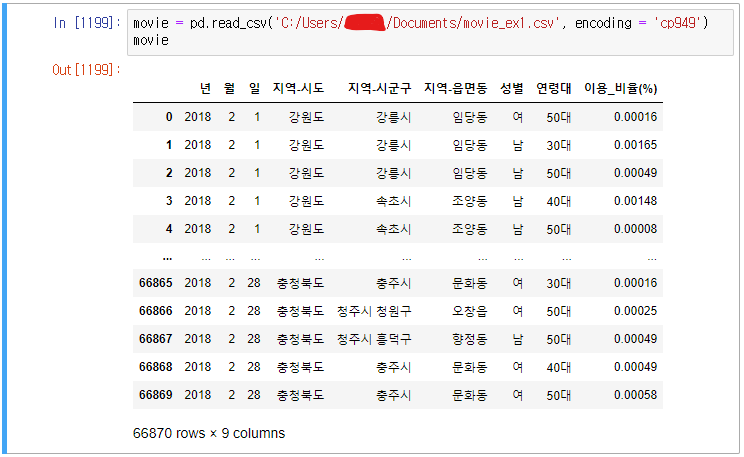
날짜 컬럼 생성
년/월/일 컬럼 삭제
컬럼 재배치

'배우기 > 복습노트[Python과 분석]' 카테고리의 다른 글
| [복습] Python | 분석 | 랜덤포레스트(Random Forest, RF)(1) + 하루끝(20240126) (0) | 2024.01.30 |
|---|---|
| [복습] Python 자료구조(6) (array) (0) | 2024.01.29 |
| [Python] 의사결정나무(Decision Tree) 시각화 하기 (0) | 2024.01.27 |
| [복습] Python | 분석 | 의사결정나무(Decision Tree) (2) (0) | 2024.01.27 |
| [복습] python 업무 능력 향상에 좋은 연습문제(라벨인코딩에 대하여) (0) | 2024.01.26 |



