https://metime.tistory.com/293
위의 게시글에 이어서 join을 더 살펴보자.
예) student.csv, exam_01.csv join 시, index를 사용한 join

자료를 불러와 공통 컬럼인 STUDNO 를 index 처리하였다.
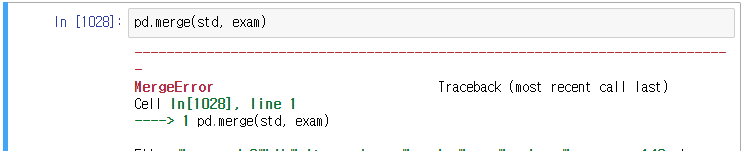
MergeError: No common to perform merge on. 이라는 에러가 발생한다.
공통 index를 join 할 때에는 그냥 merge만 해서는 안되고 다음의 옵션을 넣어야 한다.

index 관련 옵션을 True 로 설정하면 정상 출력된다.
index값을 사용하여 두 데이터를 join한 것이다.
join 연산
1. pd.merge
- equi join, natural join, cross join, outer join 지원
- 다중컬럼 join 가능
- 3개 이상의 객체 join 불가
pd.merge는 non-equi join을 지원하지 않는다.
2. non-equi join
non-equi join 해결방법
예) gogak.csv, gift.csv 파일을 읽고 각 고객별 가져갈 수 있는 사은품을 출력하시오.

1) 사용자 정의 함수
먼저 스칼라테스트를 해보면 다음과 같다.

자료구조는 시리즈 형태로 나타난다.
그런데 시리즈여서 하나하나 상품명이 출력될 때마다 Name: GNAME, dtype: object 가 출력된다.

잘린 코드는 아래와 같다.
print(gift.loc[(gift['G_START'] <= 320000) & (320000 <= gift['G_END']), 'GNAME' ].iloc[0])
이렇게 출력하면 Name: GNAME, dtype: object 없이 스칼라로 리턴된다.
전체 적용을 위한 함수 생성 및 mapping

f_gift = lambda x : gift.loc[(gift['G_START']<= x) & (x <= gift['G_END']), 'GNAME'].iloc[0]
gogak['POINT'].map(f_gift)
2) sql 문법을 사용한 처리(sqldf)
먼저 처음 실행할 때에는 cmd를 열어 아래를 입력한다.
pip install pandasql
그리고 IDE로 돌아와
import pandasql
from pandasql import sqldf
로 설정하면 sqldf 사용이 가능해진다.

3) cross join을 사용한 데이터 선택 방식

3번의 경우 성능에 좋지 않아 가장 비추하는 방식이다.
'배우기 > 복습노트[Python과 분석]' 카테고리의 다른 글
| [복습] Python 데이터의 이동(shift) (0) | 2024.01.25 |
|---|---|
| [복습] Python 파이썬에서의 SQL문법(pandasql 패키지 sqldf 함수) (0) | 2024.01.24 |
| [실습문제] 2024. 1. 18.(목) (1문제) (0) | 2024.01.24 |
| [복습] Python 파이썬에서의 join(pd.merge) (1) (0) | 2024.01.22 |
| [복습] Python DBMS 연동 (1) | 2024.01.22 |



