리스트는 R의 벡터와 유사한 자료구조이다.
다른 점이 있다면 단순하게 여러 개를 묶는 과정이라 중첩구조도 가능하며, 서로 다른 데이터 타입이 들어가기도 한다.
1차원이라고 하면 리스트도 가능하고 시리즈도 가능하다. 그러나 대용량 자료를 처리하려면 자료구조가 단순할수록 좋다. 그래서 1차원 자료구조를 선택하라고 한다면 가벼운 리스트부터 고려하는 것이 좋겠다.
리스트의 불편한 점으로는, 모든 게 안된다고 보면 된다. 단순히 쌓는 것 외에는 어떠한 것도 되지 않는다.
R에서는 벡터 연산이 되는데 리스트는 벡터 연산이 되지 않는다(시리즈는 가능).
c(1, 3, 5) + 10 가 11, 13, 15 이렇게 되지 않는다는 의미이다.
리스트는 리스트만 연산이 가능하다.

이렇게 10을 더하면 에러가 난다.
차근차근 리스트에 대하여 공부해보자.
1. 생성
- 대괄호를 사용하여 생성: []
- list 함수를 사용하여 다른 자료구조를 리스트로 변경 가능ㅎ

이렇게 생성이 가능하다.
2. 연산
위에서처럼 l1+10과 같이 숫자와의 연산은 불가하다(벡터 연산 불가)
그럼 l1+l2는 어떻게 될까?

리스트의 확장이 된다. 즉 리스트의 결합, 원소 추가의 느낌이다.
dir(l1) # 리스트가 호출 가능한 함수의 목록을 보여준다(=메서드)

여기서 함수와 메서드의 차이를 알아보자
함수는 기능을 가진 객체이다(input → output)
함수는 인수를 모두 괄호 안에 전달한다
예) map(func, iter1)
메서드는 적용할 대상이 앞에 있고 나머지 인수만 괄호 안에 전달한다. 즉, 객체가 함수를 호출하는 방식이다.
예) l1.append(6)
메서드는 객체 우선순위이다.
함수와 메서드의 차이는, 함수는 대상에 자료구조의 영향을 사실상 받지 않는다.
메서드는 l1이 호출하는 것이다. append는 series가 오면 호출이 불가하다.
함수는 어떤 객체를 써도 상관이 없는 방면 메서드는 반드시 호출할 대상이 정해져 있다. 즉 궁합이 있다는 의미이다.
파이썬은 왜 메서드를 만들었을까? 함수를 만들어두면 어떤 객체가 와도 문제가 없을텐데 말이다.
아무래도 객체가 나오게 되면 객체에 적합한 기능을 구현할 수 있도록 객체에 따라 분리하기 시작한다.
예를 들어 숫자로 구성된 2차원 매트릭스가 있다면(파이썬의 경우 array, data frame), 이걸로 행렬 곱 연산을 하고자 할 때 array로 만들면 될 일을 굳이 사용자가 data frame을 만들어 array에 사용할 function을 불러오면 사용이 되지 않기 때문이다. 따라서 그 객체만이 사용할 수 있는 메서드를 만들어 둔다.
메서드의 장점은 확장이 용이하다는 것이다.
다시 한번 주의할 점으로는 메서드는 반드시 적용 가능한 객체 타입이 정해져 있다는 것이다.
예를 들어 append 메서드는 리스트에만 전달이 가능하며, 시리즈에서는 사용이 불가하다.
예제) 메서드 적용 과정

시리즈는 아래와 같이 리스트와 출력 구조가 다르다.

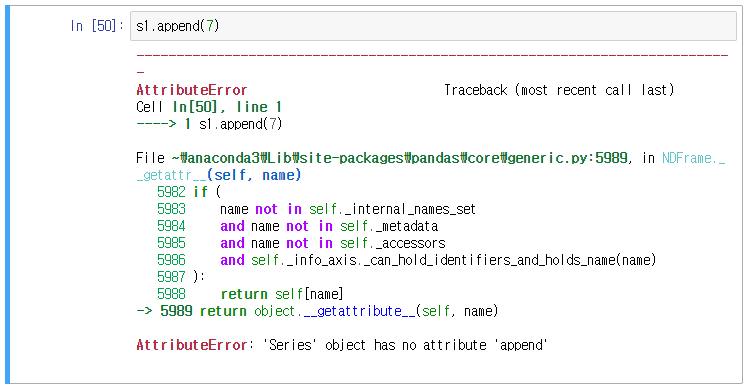
시리즈에 append 메서드를 전달하니 AttirbuteError: 'Series' object has no attirbute 'append' 라는 속성 에러가 뜬다.
호출 가능한 대상이 아니라는 에러로 이런 에러는 잘 눈여겨 보도록 하자.
예제) 함수와 메서드의 차이

여기서는 함수로, 함수는 어떤 객체를 써도 상관이 없다.
numpy 모듈과 리스트는 같은 패키지 안에 있는 자료구조가 아닌데도 사용 가능하다. 함수이기 때문이다.
따라서 리스트가 들어가도 되고, array가 들어가도 되고, data frame이 들어가도 된다.

위와 같이 array에 적용 가능한 메서드 목록이 사전에 정의되어 있는데, 그걸 호출하게 되면 정상 출력이 된다. 이는 메서드이다. array 객체 만이 호출할 수 잇는 array전용 sum 메서드이다.

위는 리스트이기 때문에, 리스트는 sum 메서드가 없기 때문에 에러가 난다.

이렇게 기본함수 sum으로 리스트 sum이 가능하다.
다시 리스트의 연산으로 돌아와서,
리스트 + 리스트는 확장 개념이 된다.

위의 l4처럼 중첩 선언이 가능하며, 중첩으로 들어간 리스트의 원소 개수는 4개로 출력이 된다. [4, 5]를 하나의 원소로 봄.

l4 곱하기 4를 하면 l1을 네 번 더한 값이 출력되며 리스트의 합은 리스트의 확장이 되므로 4번 반복된다.
리스트는 가장 가벼운 자료구조로 다른 객체를 쓰는 것보다 리스트를 사용하는 것이 속도에 좋다. 앞으로도 리스트 자료 구조를 많이 사용하게 될 것이다.
3. 색인

위처럼 색인이 가능하다.
R처럼 동시에 여러 개의 포지션 전달은 불가하다. 즉 두 번째 원소와 다섯 번째 원소만 불러올 수 없다는 의미이다.
그리고 boolean indexing도 불가하다 (l1[l1>3] 불가)
4. 메서드
dif(list) 리스트에서 사용 가능한 메서드가 무엇이 있는지 확인할 수 있다.
즉, 리스트에서 호출 가능한 메서드 목록 확인
1) 원소 추가

append 메서드를 사용하면 원소 추가가 가능하다(즉시 반영)
append 말고 extend 메서드도 있으나 정수 전달이 불가하다. 반드시 list도 전달하여야 한다.
어떻게 보면 원소 추가가 아니라 원소 확장 개념인 느낌이다.

즉 아래와 같이 써야한다.

마치 l1 + [7] 과 같은 개념이지만, extend 메서드는 즉시 반영이 된다.
l1 = l1 + [7] 처럼 써야 하고 extend는 바로 l1.extend([7]) 이 가능하다는 의미이다.
파이썬에서 출력이 아니라 원본을 직접 바꾸는 행위는 리스트의 메서드 행위가 거의 유일하다.
append는 원소가 마지막에 추가가 되는데 위치 같은 걸 전달하여 중간에 추가하는 방법도 있다.
insert 메서드를 사용하면 된다.

2 위치에 100을 삽입하겠다는 의미이다. 파이썬은 0부터 시작하므로 2위치라는 것은 세 번째에 100이 들어간다는 의미이다.
정리하자면 원소 추가는 append, extend, insert가 있다. 보통 append를 많이 쓰게 될 것이다.
2) 원소 삭제
원소 삭제는 remove를 사용한다.

위치를 지정하여 삭제하고 싶다면, del 함수를 사용하면 된다.

내가 del 함수를 여러 번 눌러서 원소가 좀 많이 사라지긴 했는데,, l1에 있는 5번째 원소를 지우려면 위처럼 del함수를 사용하면 된다.
del은 함수이므로 모든 것을 지울 수 있다. 객체도 지울 수 있으며, l1도 지울 수 있다.
위치 원소를 삭제할 수 있는 다른 메서드도 있다.
pop() 이라는 메서드가 있는데 아래와 같이 사용한다.

특정 위치의 값을 삭제하면서 화면에 삭제할 값을 출력한다. 디폴트 삭제 위치는 맨 마지막이다.
그래서 마지막 원소 50을 출력시켜주면서 지워준다.
주피터 노트북에서는 pop이 안되는데, spyder에서 pop을 쓰면 50값을 띄워주면서 삭제시킨다.
만일 50을 안 띄우고 삭제하고 싶다면
_ = l4.pop(-1) 하면 된다.
삭제를 하면서 출력을 원치 않을 때에는 _ 를 앞에 쓴다. _는 표준 출력을 버릴 때 사용한다.
중요한 것이므로 기억해두자.
3) 정렬

정렬을 할 때에는 sort 메서드를 사용하면 된다.
즉시반영이며 디폴트는 오름차순 정렬이다.
내림차순은 다음과 같이 하면 된다.

4) 포함 횟수
count 메서드를 사용하면 원소가 포함된 횟수를 출력하여준다.
l6에는 2가 두 개 있어서 아래와 같이 2를 출력해주었다.

연습문제를 풀어보자.
list1 = [1, 3, 10, 3, 5, 22]
1) 위 리스트의 세 번째 값을 100으로 변경

2) 위 리스트를 내림차순으로 정렬

3) 정렬된 리스트에 맨 마지막에 200, 300 추가

4) 두 번째 원소 삭제

'배우기 > 복습노트[Python과 분석]' 카테고리의 다른 글
| [복습] Python 문자열 메서드 (0) | 2024.01.09 |
|---|---|
| [복습] Python 원소별 반복과 사용자 정의 함수(1) (0) | 2024.01.05 |
| [복습] Python 자료구조(1) (0) | 2024.01.05 |
| [복습] Python 산술연산자 (0) | 2024.01.05 |
| [복습] Python 모듈, 모듈 호출하기 (0) | 2024.01.05 |

