문자열 치환(삭제) 함수인 replace는
replace(원본대상, 찾을 문자열[, 바꿀 문자열])
형태로 변형된다.
아래 여러가지 방법으로 실습을 해보았다.

replace('abcba', 'ab', 'AB') 는 abcba에서 앞의 ab를 AB로 바뀌었다. 여기서 보면 ab는 바꾸었으나 ba는 바꾸지 않았다.
즉 같은 문자열인 ab에만 영향이 간 것을 알 수 있다.
replace('abcba', 'ab')는 바꿀 문자열을 생략한 것으로 바꿀 문자열을 생략하면 ab를 없앤다는 의미가 되므로 ab가 삭제된다.
replace('abcba', 'ab', '')는 바로 직전 실습과 마찬가지로 ab를 작은따옴표 안으로 바꾼다는 의미인데 작은 따옴표 안에는 아무 내용도 없으므로(스페이스바로 띄운 공란 조차 없음) ab가 삭제가 된다.
마지막으로 replace ('aaaabcdadfd', 'a', '')의 경우에는 해당 단어의 모든 a를 삭제하게 된다.
정리하자면 replace 본 기능은 치환이며, 바꿀 문자열을 생략하면 찾을 문자열을 제거한다.
바꿀 문자열에 빈 문자열('')을 전달하게 되면 찾을 문자열을 제거한다.
여러 예제를 풀어보자.
STUDENT에서 각 3, 4학년 학생의 이름, 학년, 전화번호를 출력해보자. 단 이름의 두 번째 글자는 마스킹 처리한다

replace를 배워놓고 나는 첫 번째 줄 방법으로 문제를 풀었다(하지만 끝까지 읽을 것, 이 풀이가 옳음).
두 번째 선생님이 보완해주신 방법을 풀이해보면,
1) replace에 원본대상인 name을 넣고
2) 찾을 문자열에 name에서 두 번째에서 한 글자인 글자를 추출한 후에,
3) 그 단어를 * 로 치환한다고 작성하면 정답이 리턴된다.
★ 주의할 것. 이 풀이는 정답이 될 수 없다. 이름이 '김나나' 인 경우는 김**로 리턴될 것이다.★
이 점을 설명해주시기 위해 보완해주신 풀이이다.
그러므로 내가 풀이한 방법으로 풀어야 할 것 이다.
그리고 where 절에서 주의해야 할 점이 있다.
처음에 나는 부등호로 3학년보다 크거나 같다(>=)를 사용했는데, 학년에는 3.5학년이라는 것이 없다. 아마 학년은 숫자처럼 보이지만 문자 형태일 것이다.
등호를 넣어도 답이 리턴되지만 성능에 좋지 않으므로 in을 사용하도록 하자.
다음문제. STUDENT에서 주민등록번호 뒷자리를 모두 마스킹 처리해보자.
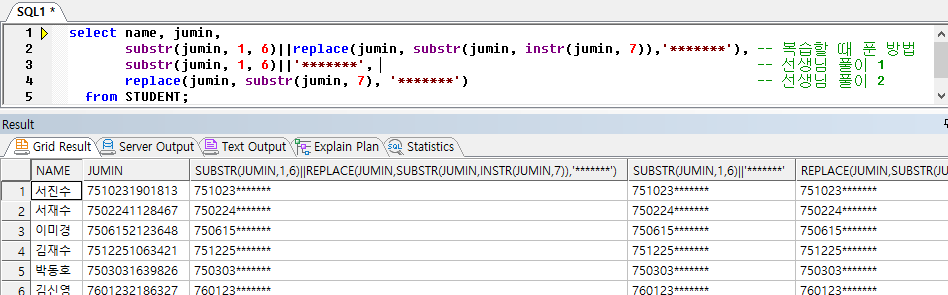
복습할 때 다시 풀어봤는데 코드가 왜 이렇게 길어지냐.. 슬프다.
뭔가 쓸 데 없는 걸 여러 번 반복한 느낌이다.
어쩌면 선생님 풀이 1과 비슷한 결이지만 나는 굳이 뒤의 7자리를 다시 대체했다면 선생님은 바로 생년월일에 *******을 붙이셨다.
선생님의 두 번째 풀이를 보면 바로 replace를 적용하여 jumin을 불러와서, 뒤의 7자리를 추출한 번호 그대로를 *******로 치환한 것을 알 수 있다.
다음은 translate 함수이다.
제목에 굳이 replace 옆에 콤마 찍고 translate 쓰지 않고 따로 써 둔 이유가 있다.
먼저 translate는 오라클에만 있는 함수이며 replace와의 차이가 있다.
replace는 단어를 치환하는 의미가 강하다면
translate는 글자를 치환한다. 번역기 기능을 하는 것이다.
이렇게 들었을 땐 이해가 잘 되지 않았는데 실습을 해보니 이해가 되었다.

같은 abcba를 ab를 AB로 바꾼다고 작성하였다.
replace는 ab 그대로를 AB로 바꾸었고 ba는 건들지 않았다.
translate는 ab 를 'a' or 'b' 의 느낌으로 처리한다는 인상이 강했다.
그냥 a와 b라면 싹다 바꿔버렸다. c 빼고 다 바뀐 거 보면 그러하다.
필기로는 1:1 치환이라고 해두었다.
replace보다는 사용 빈도는 적으며 각각 a->A, b->B 치환한다.
이게 왜 번역기 기능을 한다고 설명하신건지는 이해가 되지 않았다.
번역이라고 하면 A언어를 B언어로 바꾸는 것이라고 이해되는데...
그냥 일단 실습한 대로 이해하고 나중에 수업시간에 질문해봐야겠다.
translate의 또 다른 특징으로 글자의 개수를 다르게 하면 출력되는 형태도 다르다.

첫 줄인 translate('abcba', 'ab', 'AB') 는 위의 실습에서 보았듯이 BA도 바뀌어 리턴된 것을 알 수 있다.
그런데 translate('abcba', 'ab', 'A')만 하면 ab와 ba 자체를 그냥 A로만 바꾸었다.
translate('abcbabab', 'ab', 'AB') 또한 모든 a, b를 다 바꾸었다.
translate('abcba', 'ab', 'ABC')는 C는 무시된 채로 출력된다. 두 번째로 입력한 찾을 문자열 기준으로 1:1 치환임을 기억하자.
마지막으로 translate('abcbabb', 'ab', '')로 입력하면 모두 사라진다. 그러나 선생님께서는 번역이 주 기능이라 온전히 삭제 기능은 아니라고 말씀하셨다. 즉 개발자의 실수인지 의도한 것인지는 모르겠으나 번역 기능을 하는 데 우연히 발견된 케이스라고 하셨다.
정리하자면
translate(원본대상, 찾을 문자열, 바꿀 문자열) , 글자를 치환하는 역할을 수행한다.
찾을 문자열의 길이 > 바꿀 문자열의 길이 의 경우 짝이 맞지 않는 글자는 삭제처리가 된다.
다음은 연습문제를 풀어보자
emp 테이블에서 사원번호를 모두 6자리로 변경해보자. 사원번호 앞에는 0을 삽입한다.

emp 테이블에서 sal 뒤에 만원을 붙여 출력해보자.

student 테이블의 ID에서 0을 삭제해보자

마지막으로, emp 테이블에서 각 직원의 이름과 입사연도를 출력해보자.
참고로 이 문제는 문자 함수까지 배운 상태에서는 풀기가 어려우며 어떤 문제가 있었는지 실습을 통해 확인해보라고 하셨다.

배웠던 substr 함수를 사용하여 연도를 추출하였는데 이게 웬걸, hiredate에서 보이는 네 자리 연도를 추출하니 온전히 추출되지 않고 YYYY의 앞 YY가 생략된 채로 추출되었다.
아무리 머리를 굴려봐도 배운 선 안에서는 해결이 되지 않았는데 이는 hiredate의 속성이 DATE이기 때문이다.
이는 날짜함수를 배우면서 해결할 수가 있는데 다음 글에서 마저 복습해보도록 하겠다.



