데이터 구조 변경에 대하여 어제 배운 내용에 복습 및 이어서 작성하려고 한다.
https://metime.tistory.com/162
[복습] R(programming language) 데이터 구조 변경(long, wide) + 하루끝(20231206)
1. 데이터의 분류 1) long data(=tidy data) - rdbms의 데이터 형식이다(relationshop dbms). 하나의 속성별로 컬림이 된다. 여기서 속성이란 하나의 관찰 대상으로 데이터로 표현할 수 있는 값을 의미한다. 예
metime.tistory.com
1. 데이터 분류
1) long data(=tidy data)
- rdbms의 데이터 형식으로 하나의 속성이 하나의 컬럼이 되는 형식이다.
- join / group by 연산이 가능하다.
2) wide data
- cross table
- 요약 정보(직관적), 행별 열별 연산이 용이하다.
- join 불가
- 잦은 컬럼 변경(추가, 삭제) 발생
어제 이 정도로 정리 한 것 같다.
2. 데이터 구조 변경
1) wide → long : stack
기본함수 중에 base::stack 이 있는데 쓸 일이 없다고 하셨다. 설명은 나중에.
reshape2::melt
reshape2::melt(data = , # 원본데이터(데이터 프레임)
id.vars, # 고정컬럼(stack 제외 컬럼)
measure.vars, # stack처리 컬럼(생략시 id.vars 명시된 대상 제외한 나머지 )
variable.names = 'variable', # stack 처리된 컬럼 이름
....,
na.rm = FALSE,
value.name = 'value', # value 컬럼의 이름
factorsAsString = TRUE) # factor로 들어오는 걸 문자열 처리 하겠냐는 의미(신경쓰지 않아도 됨)
예제로 바로 적용해보겠다.
예) melt_ex.csv 파일을 읽고 long data로 변환하여라.

연습문제
melt_ex.csv, melt_ex_price.csv 데이터를 읽고 연도별 매출의 총액을 출력하여라.

연습문제
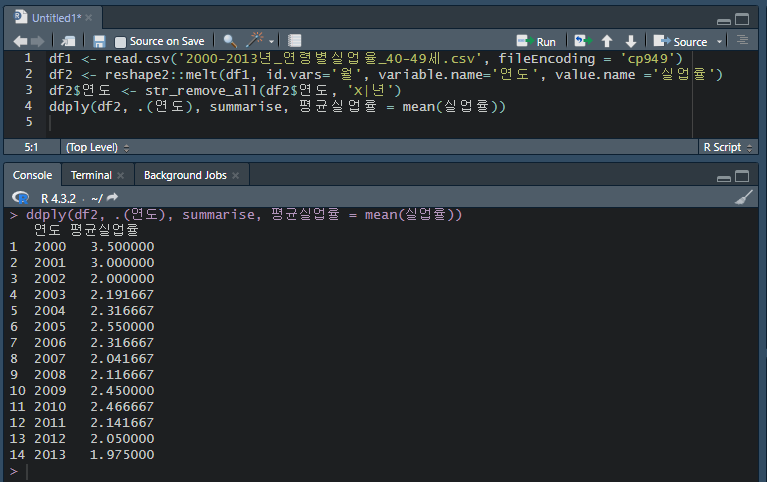
2000-2013년 연령별실업율_40-49세.csv 파일을 읽고 long data로 변경 후 연도별 평균 실업률을 출력하여라.
2) long → wide: unstack
보고서 작성 또는 시각화 할 때 필요
reshape2::dcast(data = , # 원본 데이터 프레임
formula = , # 행에 배치할 대상 ~ 컬럼에 배치할 대상
fun.aggregate = , # 요약함수
........., # 요약함수에 추가 전달 인수
margins = , # 주변 합(평균, 수, 합 등 fun.aggregate에 의해 달라짐)
subset = , # 추가 조건을 전달하여 원하는 데이터만 선택(잘 안씀)
fill = , # NA 치환값
drop = TRUE, # unstack 처리 후 모든 값이 NA인 행을 삭제하는 옵션(이론적으로 존재하는 옵션)
value.var = ) # value 컬럼(생략 시 맨 마지막 컬럼 선택)
어제 했던 googleVis::Fruits 에서,
이어서 3) 과일 이름별 연도별 Sales의 총 합에 대한 margin을 출력하여라

Line 1은 fun.aggregate를 쓰지 않았을 경우 length가 출력이 된다.
Line 3처럼 총 합을 구하려면 sum을 넣어야 한다.
예) fill 옵션 사용 예제(연도별 제품별 판매량에 대한 교차표)

이 데이터에서는 일부러 2001년 americano 행을 지웠다(Line 2).
이제 wide data에서 삭제된 셀에 대한 자리를 채워야 하는데 fill 옵션이 없는 경우는 NA를 채우고, fill=0을 주면 NA값이 0으로 대체된다.
연습문제
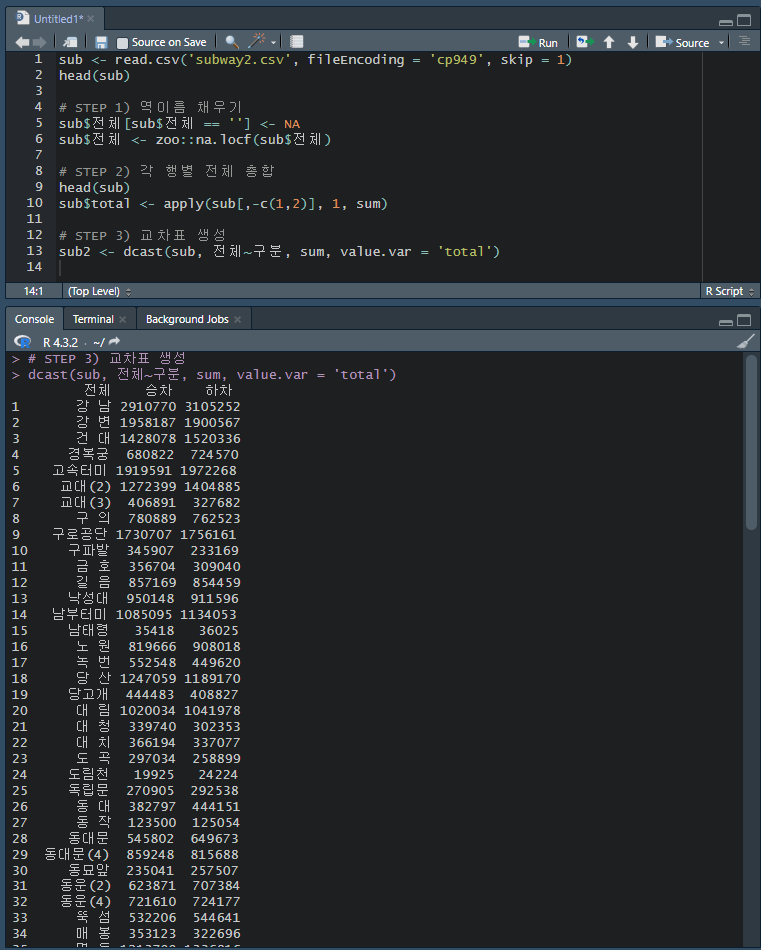
subway2.csv 파일을 읽고
승차 하차
서울역(1) 총합 총합
시청(1) 총합 총합
...
의 형태로 출력하여라.
※참고 행별/열별 총합과 평균 리턴 함수
위의 Line 10에 행별 총합을 구할 수 있는 함수가 있다.
행별/열별 총합과 평균 리턴 함수 전체이다.
rowSums(sub[,-c(1,2)])
rowMeans(sub[,-c(1,2)])
colSums(sub[,-c(1,2)])
colMeans(sub[,-c(1,2)])
합과 평균만 있으며 최소값이라고 하여 rowMins 이런 게 있는 것은 아니다. 위의 4개만 존재한다.
[연습문제]
위 sub2 데이터를 사용하여 승차가 가장 많은 역이름을 출력하여라.

※ 참고 - 최대/최소를 갖는 위치 리턴 함수
which.max()
which.min()

연습문제
card_history.csv 파일을 읽고
1) 일자별 가장 지출이 많은 품목을 확인하여라.

2) 각 지출 품목별 가장 많은 지출을 한 일자를 확인하여라.

'배우기 > 복습노트[R과 분석]' 카테고리의 다른 글
| [실습문제] 2023. 12. 7.(목) (1문제) (0) | 2023.12.08 |
|---|---|
| [복습] R(programming language)의 파일 입출력 + 하루끝(20231207) (0) | 2023.12.07 |
| [복습] R(programming language) 데이터 구조 변경(long, wide) + 하루끝(20231206) (0) | 2023.12.07 |
| [복습] R(programming language)에서의 구조적 문법(dplyr) (0) | 2023.12.07 |
| [복습] R(programming language) 집합연산자 (0) | 2023.12.07 |



