우선 join이란 참조 테이블에 참조 조건을 걸어 값을 가져오는 행위이다.
join 메커니즘은 아래와 같다.
step 1) 원본 table에서 참조 조건을 걸 대상(상수) 선택
step 2) 참조 table에서 참조 대상과의 조건을 선택
step 3) 해당 조건에 맞는 대상을 참조 table에서 가져오기
R에서는 merge로 join 연산이 가능하다(R, Python 공통).
equi join만 가능하며(non-equi join 불가),
inner join이 기본 연산이다(outer join 지원, full outer join 까지 지원)
natural join이 기본이다.
예제를 풀어보자.
emp, dept를 사용하여 각 직원의 이름, 부서명을 출력하여라.
먼저 이전에 풀이한 방법대로 풀이해보면 다음과 같다.

merge 문법을 사용해보자.
먼저 포맷부터 확인해보면 다음과 같다.
merge( x, # join 대상이 두 개(x, y가 join대상이며 데이터 프레임이어야 한다)
y, # join 대상이 두 개(x, y가 join대상이며 데이터 프레임이어야 한다)
by = intersect(names(x), names(y)), # join 컬럼(양 데이터에 같은 이름의 컬럼인 경우)
# intersect는 교집합이며 이 by를 생략하면 알아서 intersect 함.
by.x = by, # 첫 번째 데이터 프레임의 join 키를 각각 전달하고 싶을 때,
by.y = by, # 두 번째 데이터 프레임의 join 키를 각각 전달하고 싶을 때,
all = FALSE # outer join과 연관, TRUE 이면 full outer join
all.x = all # outer join과 연관, x 기준 left outer join (TRUE인 경우)
all.y = all # outer join과 연관, y 기준 right outer join (TRUE인 경우)
sort = TRUE # 정렬여부로 속도에 영향을 주므로 끄는 것이 좋다.
suffixes = c(".x", ".y")
따라서 위 merge에 대입하면,

equi는 이렇게 쓸 수 있으나 non-equi는 merge로 못 쓰므로 기존 방식도 잘 알아두는 것이 좋다.
다른 예제를 풀어보자.
student.csv와 professor.csv 파일을 읽고 각 학생의 이름과 교수 이름을 출력하여라.

위처럼 단순히 merge만 해서는 안된다. 0건이 리턴되었다.
이름이 같은 컬럼이 여러 개 있기 때문이다.
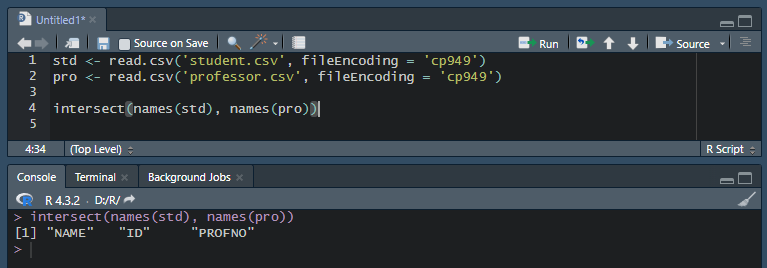
이렇게 NAME, ID, PROFNO 세 개나 이름이 같다.
이럴 때는 by 옵션을 활용하여야 한다.

15건이 출력되는데 기본연산이 inner join이어서 데이터 축소가 일어날 수밖에 없다.
여기서 outer join을 완성하고자 한다.
이 때에는 다음 옵션을 추가하면 된다.

20건이 모두 출력되었다.
emp.csv 파일을 사용하여 각 직원의 이름, 상위관리자 이름을 출력하여라
이 풀이는 self join이 된다. 그리고 같은 데이터이므로 natural join이 불가하다.

이렇게 해결하면 된다.
그렇다면 non-equi join은 어떻게 해결하여야 할까?
우선 위에 설명한 것처럼 merge는 불가하며, SQL문을 사용하는 것이 편리하다. SQL문을 사용하는 방법으로는 DBMS에서 데이터를 가져올 때 먼저 join을 수행하여 가져오거나 R에서 SQL 패키지를 이용할 수 있다.
먼저 다음 문제를 풀어보자.
student, exam_01, hakjum 데이터를 이용하여 각 학생의 이름, 점수, 학점을 출력하여라.
풀이 접근 방법은 다음과 같다.
student, exam_01을 먼저 join 한 후에 그 시험 성적을 기반으로 하여 hakjum을 가져온다.

비슷한 문제가 하나 더 있다.
gogak.csv 파일과 gift.csv 파일을 사용하여 각 고객이름, 상품명을 출력하여라(상품은 포인트로 가져갈 수 있는 가장 좋은 상품 하나만 출력하여라).

여기까지 join 끝!
참고로 sqldf 패키지 사용법을 작성해두겠다.
sqldf 패키지란 R 내부에서 SQL을 사용하여 데이터 처리를 도와주는 패키지이다.

바로 위 문제를 sqldf 패키지를 이용하여 SQL문으로 풀어보았다.
SQL로 풀게 되면서 대소구분하지 않고 between 연산자도 쓸 수 있게 되었다.
모든 함수를 다 지원해주지 않으며 Oracle이 아닌 SQLite 문법을 지원해줘서 decode 이런 함수도 사용이 불가하다.
그러나 join은 oracle join을 지원해주긴 한다.
무엇보다도 빅분기에 포함된 패키지가 아니어서 시험 때 사용할 수 없다.
복습후기
오늘은 컨디션이 좋지 않아 빨리 집으로 와서 쉬었다.
그리고 한 시 반 기상하여 복습 마무리.
이러다가 밤낮 바뀔 것 같다.
어쨌든 오늘도 간신히 따라잡았다.
'배우기 > 복습노트[R과 분석]' 카테고리의 다른 글
| [복습] R(programming language)의 숫자(수학/통계) 함수 (0) | 2023.11.28 |
|---|---|
| [실습문제] 2023. 11. 27.(월) (3문제) (0) | 2023.11.28 |
| [복습] R(programming language) NA와 NULL (0) | 2023.11.28 |
| [복습] R(programming language) 반복문(ifelse함수, for문, while문) (2) (0) | 2023.11.28 |
| [실습문제] 2023. 11. 24.(금) (2문제) (0) | 2023.11.28 |


