데이터 프레임을 살펴보기 전에 다른 자료구조들도 간단히 살펴보자.
1. 벡터
- 1차원이다.
- 서로 같은 데이터타입만 허용한다. 사용자가 임의로 다른 데이터를 넣으면 문자가 상위 개념이어서 숫자와 문자를 넣으면 문자, 논리값과 문자 넣어도 문자로 변환되어 나온다. 그러나 우선순위를 알 필요는 없다. 이렇게 값을 넣는 것이 잘못되었다는 것만 인지하자.
2. 리스트
- 사실상 1차원
- 하지만 벡터와는 다르게 key-value 구조이다. 그러다보니 2차원은 아니지만 여러 정의된 데이터를 축적할 수 있다.
즉 key 별로 데이터 축적 및 색인이 가능하다.
아직 배우진 않았지만 구조를 살펴보면 아래와 같다.
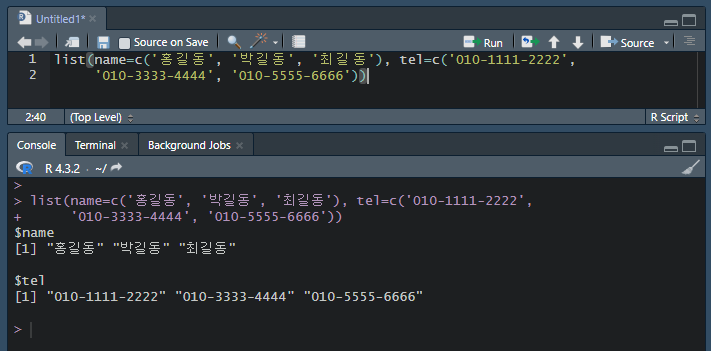
2차원이라고 생각할 수 있지만 박길동을 추출하고 싶을 때 박길동만의 정보를 [,]로 추출할 수 있다. 자세한 내용은 다음 수업 때 알 수 있겠지.
3. 행렬(matrix)
- 2차원 구조이다.
- key-value구조가 아니다.
- 단 하나의 데이터 타입만 허용하고 있다. 벡터가 확장된 개념이라고 생각하면 될 것이다. 주로 숫자들로만 구성된 대용량 데이터를 선언할 때 사용한다.
- 컬럼별로 묶어서 전달하고, 수정하고, 연산할 때에는 데이터 프레임이 좋지만 통째로 계산할 때에는 행렬이 빠르다.
즉, 목적에 따라 설계를 달리하여야 한다.
4. 배열(array)
- 다차원 구조이다.
- 단 하나의 데이터 타입만 허용한다. 벡터에 차원이 생기면 행렬, 행렬에 차원이 생기면 배열이 된다.
2차원 수치 데이터면 2차원 행렬을 쓰고 3차원 수치 데이터라면 3차원 행렬을 쓰는데 이게 곧 배열이다. 영상 분석이 보통 3차원 분석이며, 배열과 행렬이 계산이 데이터 프레임에 비하여 계산이 빠르다. key구조가 없기 때문이다.
key는 구조상 선택하고 그룹별 연산을 하는 데에 유리하다.
딥러닝 코드 짤 때 배열과 행렬을 사용하게 될 것이다.
이제 공부할 5. 데이터 프레임이다.
1. 생성
data.frame(...., # 가변형 인수 전달 방식, 여러 개를 c 없이 나열할 수 있다.
row.names= , # 위치는 가변, 그래서 row.names=라고 꼭 써야 함. 행번호 작성한다.
........., # 생략
stringAsFactors = ) # string을 Factor 처럼 사용하여라. 문자열 범주형 변환이다.
과거 버전에서는 stringAsFactors의 Default 값이 F였다.
여기서 잠시 Factor에 대하여 알아보자.
Factor 범주에서 우번 범주란, 정해져있는 범주 안에서 데이터가 생성되고 변환될 수 있는 범위이다. 꼭 문자일 필요는 없으나 대체적으로 문자이다. 예를 들어 성별(남, 여), 등급(상, 중, 하), 학년(1, 2, 3, 4) 등이 있다.

각 옵션에 따라 위와 같은 결과 차이를 보인다. 그런데 df2와 df3은 차이가 크게 없어보이는데 stringsAsFactors = T로 줬을 때 어떤 게 달라지는지 아래와 같이 확인해보겠다.

Line 10은 name 의 b가 B로 변경된 반면에 Line 11의 name b가 NA로 생성되었다.
정의된 레벨이 아니기 때문이다.
df3의 name 이라는 컬럼은 factor로 만들어져있고 factor로 정의할 때 가지고 있는 값이 factor의 레벨이 된다. 그래서 그 레벨이 아닌 값으로는 입력 및 수정이 불가하다.
factor 또한 범주형 데이터 타입의 선언 방식이므로 데이터 타입 변경이 가능하다.
factor 컬럼을 일반 컬럼으로 변경하는 방법은, 형변환을 하는 것이다.

character로 변경된 것을 확인할 수 있다.
다시 factor로 변경하려면 또한 factor로의 형변환을 하면 된다.

다시 변경하였다.

str 함수로 데이터의 내부구조를 볼 수 있는데, name 옆에 자료에서는 없던 1, 2가 표시되어있다.
R에서는 factor로 자료를 저장하면 정렬 순서대로 level number를 부여한다.
레벨 넘버는 1, 2 로 통신이 되는데 우리 눈에 보이는 건 a, b 뿐이다.
1, 2가 언제 사용되냐면 예시로 아래를 참고해보자
테스트예제로 많이 사용하는 iris 데이터 프레임인데, 꽃의 품종을 예측하는 간단한 모델링 예제이다.
많이 예제로 사용되어서 R에 iris 데이터가 저장되어 있다.

여기서 factor로 저장된 Species는 붖꽃의 품종이다.
이 자료로 산점도를 그려보자.
산점도란 x축과 y축으로 이루어져있는데 두 축의 상관관계를 시각화를 통해 알 수 있는 기법이다.
데이터를 분석하기 전에 보통 산점도를 그려 데이터를 탐색하는데 이걸 eda(Exploratory Data Analysis, 탐색적 데이터 분석) 라고 한다.

이렇게 플로팅을 하면 오른쪽 하단에 그래프가 생성된다.

꽃의 종에 따라 분포도를 구분하여 보고 싶을 때, 여기서 옵션으로 factor를 입력해주면 종별로 색이 입혀진다.


아직 해석은 어려우나 이렇게 종별로 상관관계가 있는지 확인할 수 있다.
즉, factor는 시각화 할 때 필요하고, random forest 분류 분석 모델을 돌릴 때 y 가 무조건 factor로 들어가야 하는 규칙이 있다. 그래서 이 때에도 factor를 선언한다.
즉 factor 선언이 필요한 경우는 시각화(level 별로 서로 다른 색 전달), random forest 학습 할 때 필요하다.
데이터 프레임의 생성을 기록하다가 factor 설명까지 왔다.
2. 구조

Line 1처럼 str 함수를 사용하면 사이즈를 알 수 있다.
Line 2는 행의 수, Line 3은 컬럼 수를 출력한다.
length는 본래 1차원 벡터의 개수를 가져다준다. 이걸 데이터 프레임에서 사용하면 컬럼 수를 가져다준다. 하지만 가급적 ncol을 사용할 것을 권장한다.
3. 색인
벡터의 색인과 일치하므로 넘어갔다.
여기까지가 데이터 프레임이다.
'배우기 > 복습노트[R과 분석]' 카테고리의 다른 글
| [실습문제] 2023. 11. 22.(수) (3문제) (0) | 2023.11.23 |
|---|---|
| [복습] R(programming language) 문자열 함수 정리하기 + 복습후기(20231122) (0) | 2023.11.23 |
| [복습] R(programming language) 자료구조(벡터) (2) (0) | 2023.11.22 |
| [복습] R(programming language) 연산자 정리 (0) | 2023.11.22 |
| [실습문제] 2023. 11. 21.(화) (2문제) (0) | 2023.11.22 |



